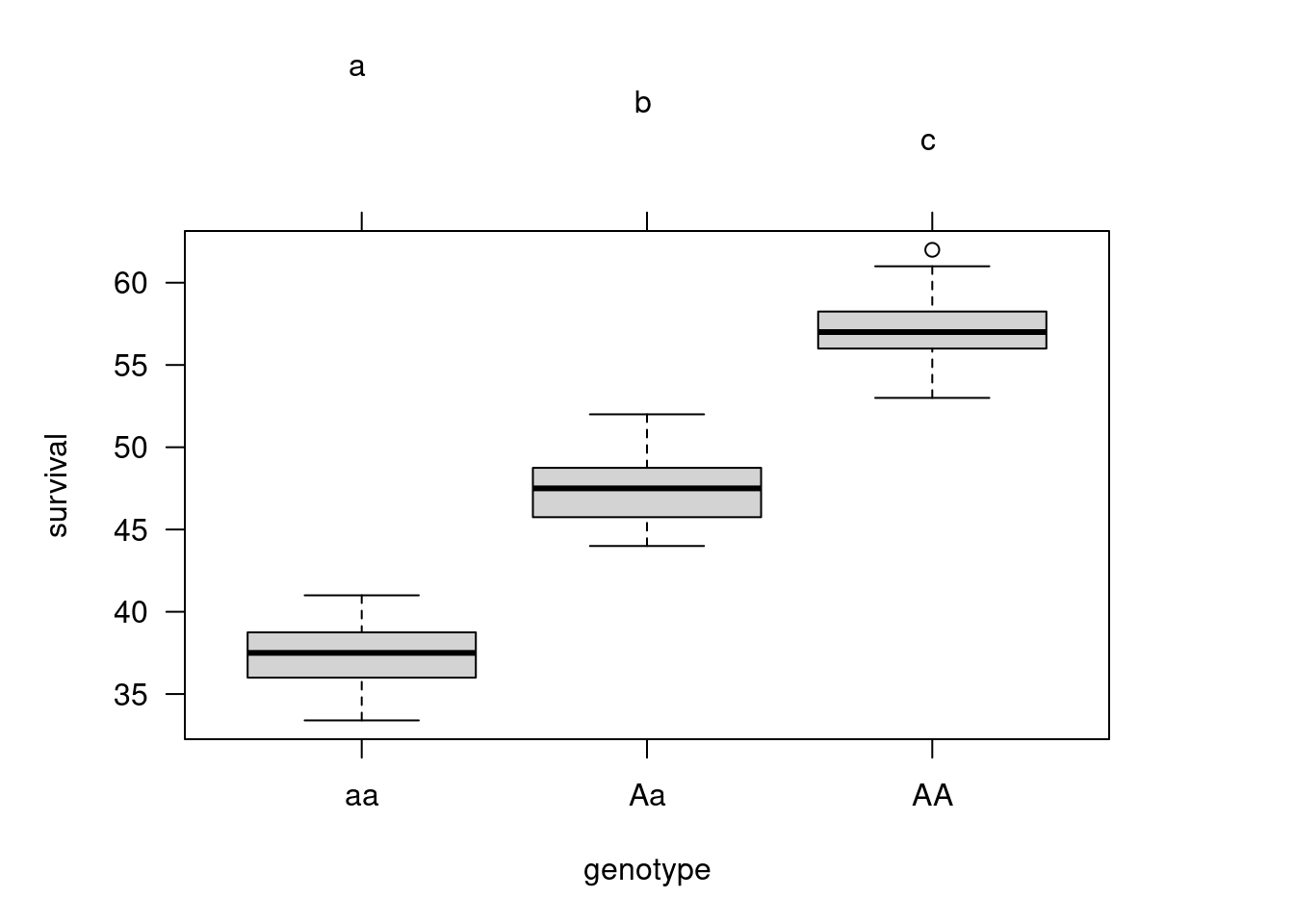lattice theme set by effectsTheme()
See ?effectsTheme for details.
12.2 Two-way factorial design with replication
Many experiments are designed to investigate the joint effects of several different factors: in a two-way ANOVA, we examine the effect of two factors, but in principle the analysis can be extended to three, four or even five factors, although interpreting the results from 4- and 5-way ANOVAs can be very difficult.
Suppose that we are interested in the effects of two factors: location (Cumberland House and The Pas) and sex (male or female) on sturgeon size (data can be found in Stu2wdat.csv). Note that because the sample sizes are not the same for each group, this is an unbalanced design. Note also that there are missing data for some of the variables, meaning that not every measurement was made on every fish.
12.2.1 Fixed effects ANOVA (Model I)
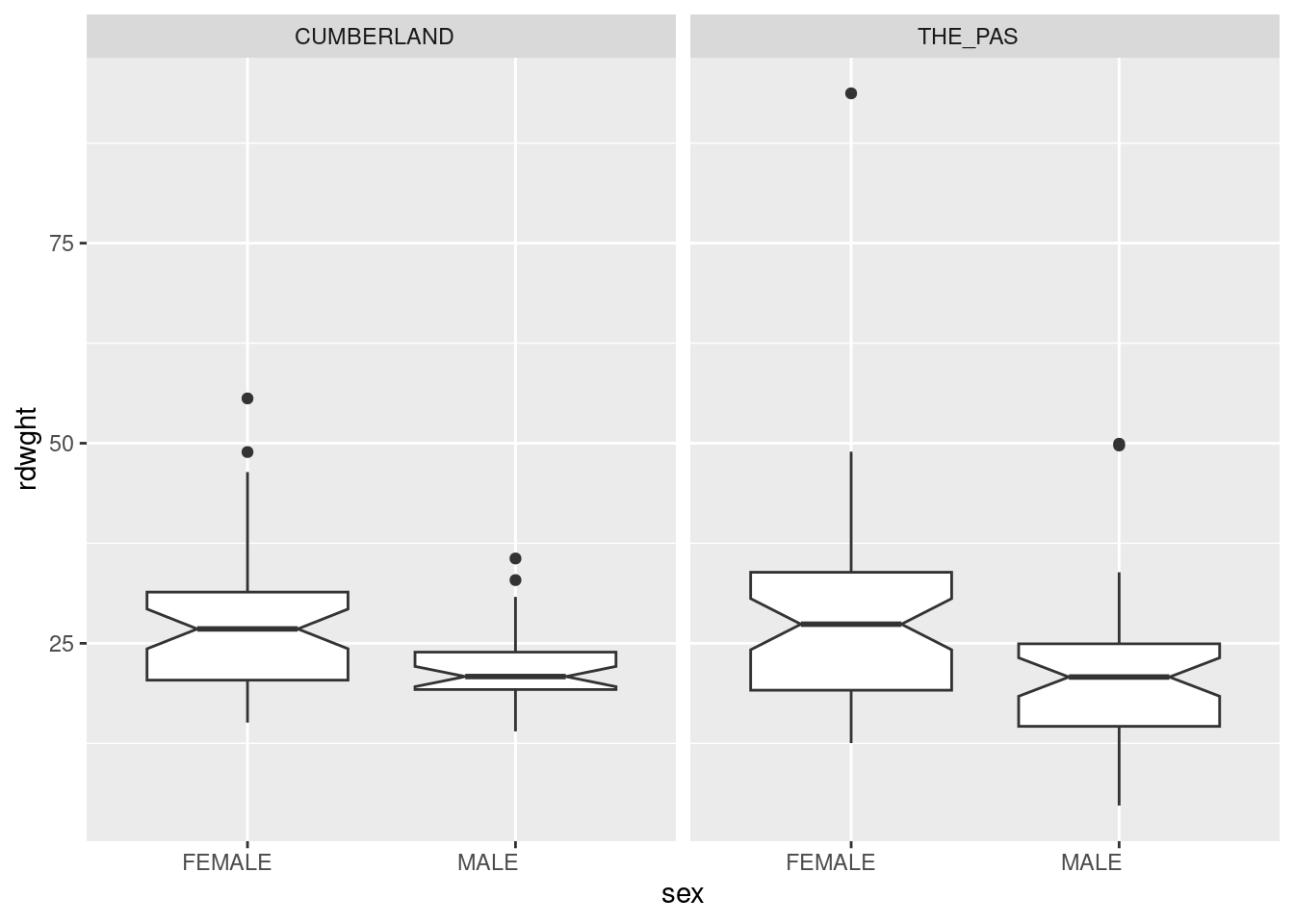
Begin by having a look at the data by generating box plots of rdwght for sex and location from the file Stu2wdat.csv .
Warning: Removed 4 rows containing non-finite outside the scale range
(`stat_boxplot()`).
From this, it appears as though females might be larger at both locations. It’s difficult to get an idea of whether fish differ in size between the two locations. The presence of outliers on these plots suggests there might be problems meeting normality assumptions for the residuals.
Generate summary statistics for rdwght by sex and location .
The summary statistics confirm our interpretation of the box plots: females appear to be larger than males, and differences in fish size between locations are small.
Using the file Stu2wdat.csv , do a two-way factorial ANOVA:
# Fit anova model and plot residual diagnostics# but first, save current par and set graphic page to hold 4 graphsopar<-par(mfrow =c(2, 2))anova.model1<-lm(rdwght~sex+location+sex:location, contrasts =list(sex =contr.sum, location =contr.sum), data =Stu2wdat)anova(anova.model1)
Analysis of Variance Table
Response: rdwght
Df Sum Sq Mean Sq F value Pr(>F)
sex 1 1839.6 1839.55 18.6785 2.569e-05 ***
location 1 4.3 4.26 0.0433 0.8355
sex:location 1 48.7 48.69 0.4944 0.4829
Residuals 178 17530.4 98.49
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Warning
Be careful here. R gives you the sequential sums of squares (Type I) and associated Mean squares and probabilities. These are not to be trusted unless the design is perfectly balanced. In this case, there are varying numbers of observations across sex and location combinations and therefore the design is not balanced.
What you want are the partial sums of squares (type III). The easiest way to get them is to use the Anova() function in the car 📦 package (note the subtle difference, Anova() is not the same as anova(), remember case matters in R.). However, this is not enough by itself. To get the proper values for the type III sums of square, one also needs to specify contrasts, hence the cryptic contrasts = list(sex = contr.sum,location = contr.sum).
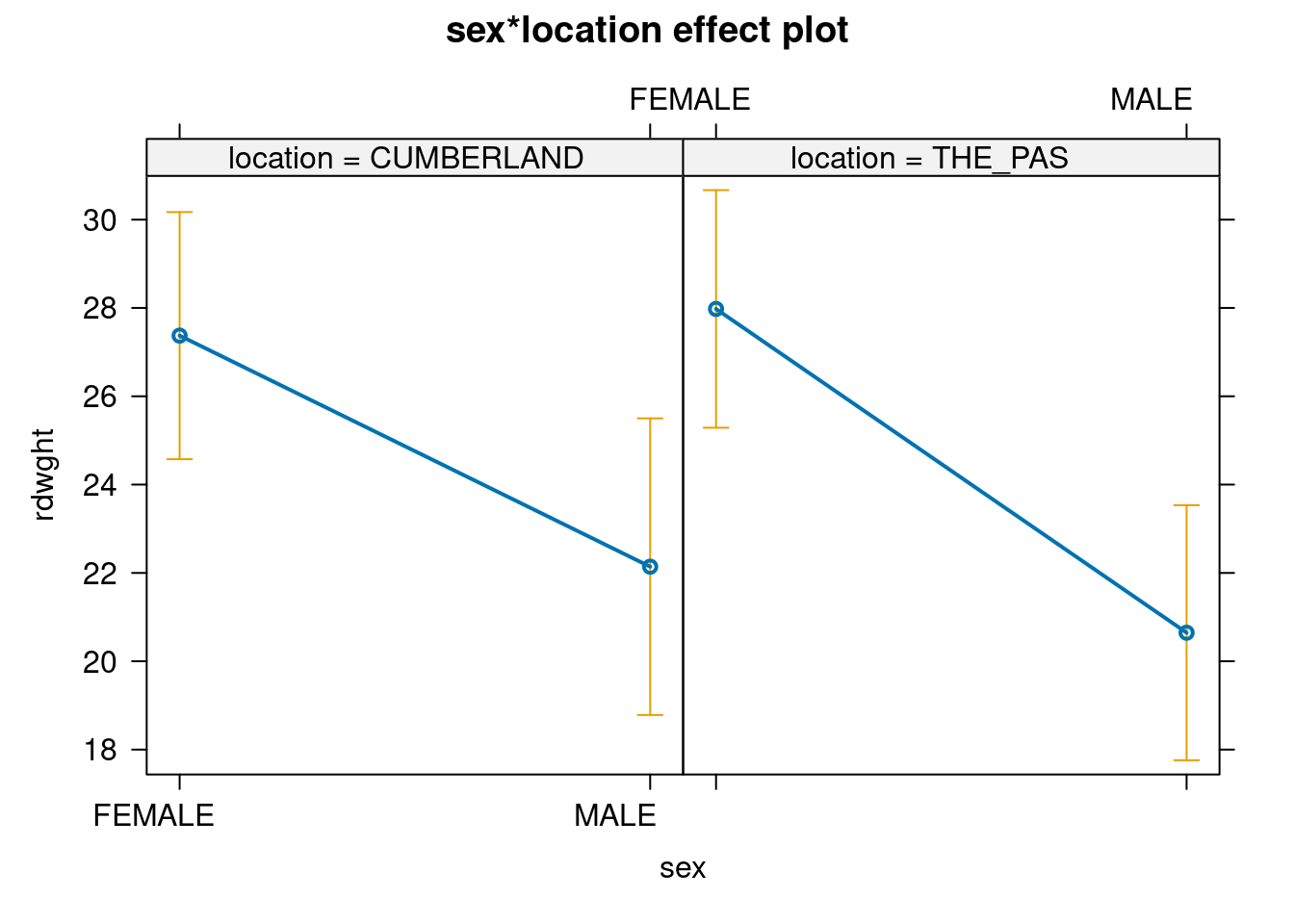
On the basis of the ANOVA, there is no reason to reject two null hypotheses: (1) that the effect of sex (if any) does not depend on location (no interaction), and (2) that there is no difference in the size of sturgeon (pooled over sex ) between the two locations . On the other hand, we reject the null hypothesis that there is no difference in size between male and female sturgeon (pooled over location ), precisely as expected from the graphs.
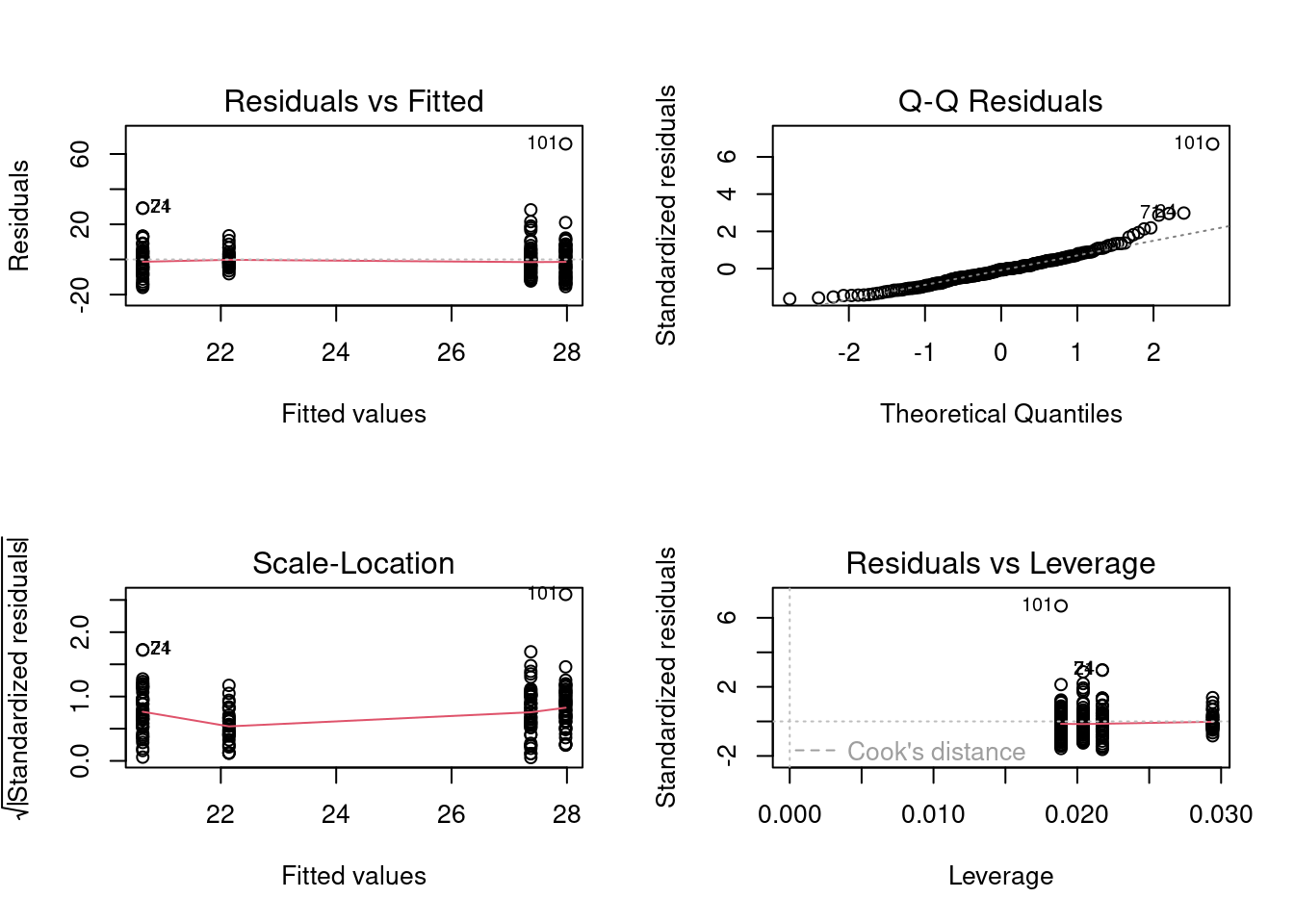
As usual, we cannot accept the above results without first ensuring that the assumptions of ANOVA are met. Examination of the residuals plots above shows that the residuals are reasonably normally distributed, with the exception of three potential outliers flagged on the QQ plot (cases 101, 24, & 71; the latter two are on top of one another). However, Cook’s distances are not large for these (the 0.5 contour is not even visible on the plot), so there is little indication that these are a concern.The residuals vs fit plot shows that the spread of residuals is about equal over the range of the fitted values, again with the exception of a few cases. When we test for normality of residuals we get:
Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 3 3.8526 0.01055 *
178
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
If the assumption of homogeneity of variances was valid, we would be accepting the null that the mean of the absolute values of residuals does not vary among levels of sex and location (i.e., group ). The above table shows that the hypothesis is rejected and we conclude there is evidence of heteroscedascticity. All in all, there is some evidence that several important assumptions have been violated. However, whether these violations are sufficiently large to invalidate our conclusions remains to be seen.
CautionExercise
Repeat this procedure using the data file Stu2mdat.Rdata . Now what do you conclude? Suppose you wanted to compare the sizes of males and females: in what way would these comparisons differ between Stu2wdat.Rdata and Stu2mdat.Rdata ?
TipSolution
Stu2mdat<-read.csv("data/Stu2mdat.csv")anova.model2<-lm( formula =rdwght~sex+location+sex:location, contrasts =list(sex =contr.sum, location =contr.sum), data =Stu2mdat)summary(anova.model2)Anova(anova.model2, type =3)
Call:
lm(formula = rdwght ~ sex + location + sex:location, data = Stu2mdat,
contrasts = list(sex = contr.sum, location = contr.sum))
Residuals:
Min 1Q Median 3Q Max
-15.917 -6.017 -0.580 4.445 65.743
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 24.5346 0.7461 32.885 < 2e-16 ***
sex1 -0.5246 0.7461 -0.703 0.483
location1 0.2227 0.7461 0.299 0.766
sex1:location1 3.1407 0.7461 4.210 4.05e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 9.924 on 178 degrees of freedom
(4 observations deleted due to missingness)
Multiple R-squared: 0.09744, Adjusted R-squared: 0.08223
F-statistic: 6.405 on 3 and 178 DF, p-value: 0.0003817
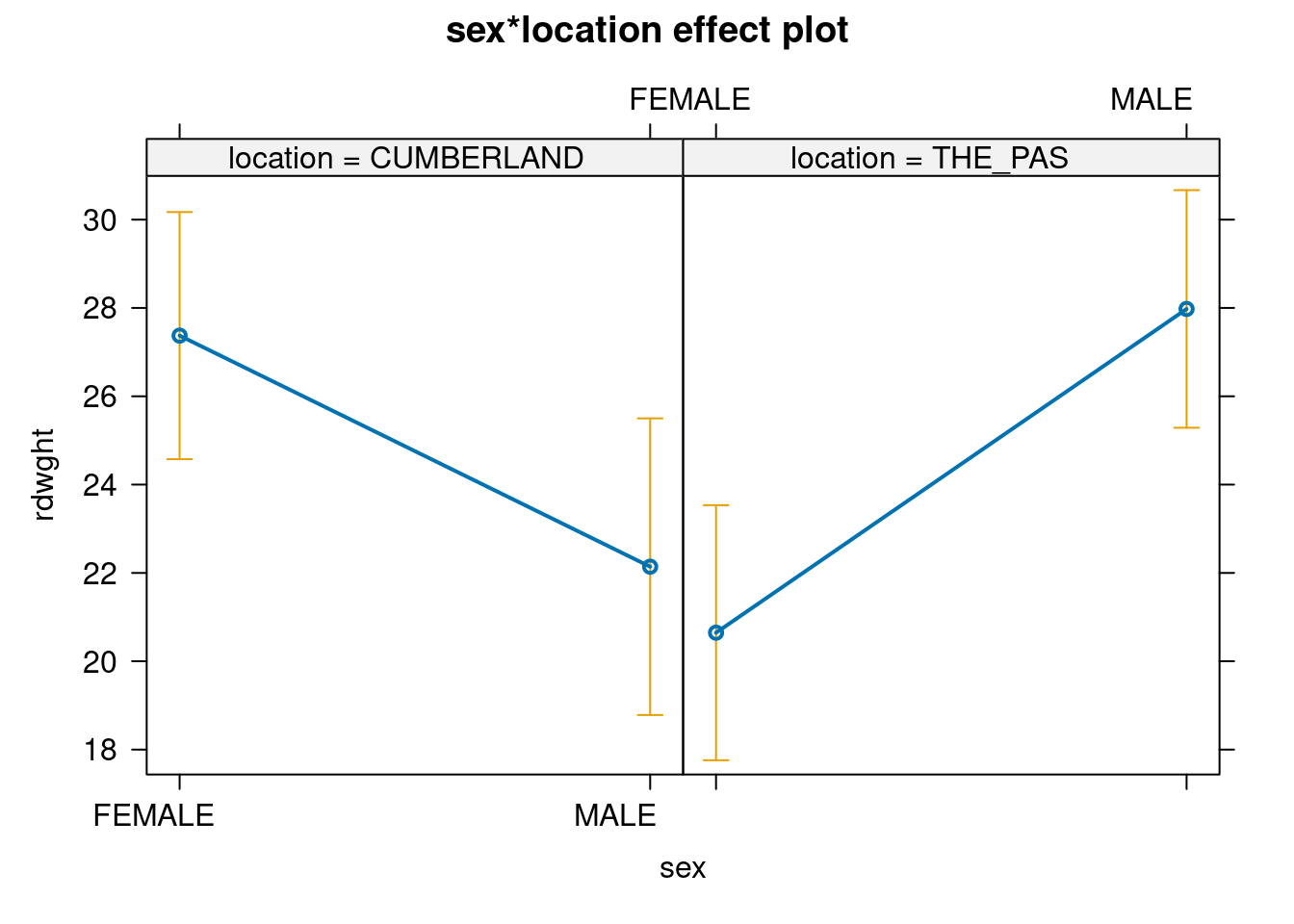
Note that in this case, we see that at Cumberland House, females are larger than males, whereas the opposite is true in The Pas (you can confirm this observation by generating summary statistics). What happens with the ANOVA (remember, you want Type III sum of squares)?
In this case, the interaction term sex:location is significant but the main effects are not significant.
You might find it useful here to generate plots for the two data files to compare the interactions between sex and location. The effect plot shows the relationship between means for each combination of factors (also called cell means). Generate an effect plot for the two models using the allEffects() command from the effects 📦 package:
Effet du sexe et du lieu sur le poids des esturgeons
There is a very large difference between the results from Stu2wdat and Stu2mdat. In the former case, because there is no significant interaction, we can essentially pool over the levels of factor 1 (sex, say) to test for the effects of location , or over the levels of factor 2 (location) to test for the effects of sex . In fact, if we do so and simply run a one-way ANOVA on the Stu2wdat data with sex as the grouping variable, we get:
Anova Table (Type III tests)
Response: rdwght
Sum Sq Df F value Pr(>F)
(Intercept) 78191 1 800.440 < 2.2e-16 ***
sex 1840 1 18.831 2.377e-05 ***
Residuals 17583 180
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Note that here the residual sum of squares (17583) is only slightly higher than for the 2-way model (17530), simply because, in the 2-way model, only a small fraction of the explained sums of squares is due to the location main effect or the sex:LOCATION interaction. On the other hand, if you try the same trick with stu2mdat, you get:
Anova Table (Type III tests)
Response: rdwght
Sum Sq Df F value Pr(>F)
(Intercept) 55251 1 515.0435 <2e-16 ***
sex 113 1 1.0571 0.3053
Residuals 19309 180
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Here, the residuals sum of squares (19309) is much larger than in the 2-way model (17530), because most of the explained sums of squares is due to the interaction. Note that if we did this, we would conclude that male and female sturgeons don’t differ in size. But in fact they do: it’s just that the difference is in different directions, depending on location. This is why it is always dangerous to try and make too much of main effects in the presence of interactions!
12.2.2 Mixed effects ANOVA (Model III)
We have neglected an important component in the above analyses, and that is related to the type of ANOVA model we wish to run. In this example, Location could be considered a random effect, whereas sex is a fixed effect (because it is “fixed” biologically), and so this model could be treated as a mixed model (Model III) ANOVA. Note that in these analyses, R treats analyses by default as Model I ANOVA, so that the main effects and the interaction are tested over the residuals mean square. Recall, however, that in a Model III ANOVA, main effects are tested over the interaction mean square or the pooled interaction mean square and residual mean square (depending on which statistician you consult!)
Working with the Stu2wdat data, rebuild the ANOVA table for rdwght for the situation in which location is a random factor and sex is a fixed factor. To do this, you need to recalculate the F-ratio for sex using the sex:location interaction mean square instead of the residual mean square. This is most easily accomplished by hand, making sure you are working with the Type III Sums of squares ANOVA table.
To assign a probability to the new F-value, enter the following in the commands window: pf(F, df1, df2, lower.tail = FALSE) , where F is the newly calculated F-value, and df1 and df2 are the degrees of freedom of the numerator (sex) and denominator (SEX:location), respectively.
Note that the p value for sex is now non-significant. This is because the error MS of the initial ANOVA is smaller than the interaction MS, but mostly because the number of degrees of freedom of the denominator of the F test has dropped from 178 to 1. In general, a drop in the denominator degrees of freedom makes it much more difficult to reach significance.
Note
Mixed model which are a generalisation of mixed-effect ANOVA are now really developped and are to be favoured intead of doing it by hand.
12.3 2-way factorial ANOVA without replication
In some experimental designs, there are no replicates within data cells: perhaps it is simply too expensive to obtain more than one datum per cell. A 2-way ANOVA is still possible under these circumstances, but there is an important limitation.
Warning
Because there is no replication within cells, there is no error variance: we have simply a row sum of squares, a column sum of squares, and a remainder sum of squares. This has important implications: if there is an interaction in a Model III ANOVA, only the fixed effect can be tested (over the remainder MS); for Model I ANOVAs, or for random effects in Model III ANOVAs, it is not appropriate to test main effects over the remainder unless we are sure there is no interaction.
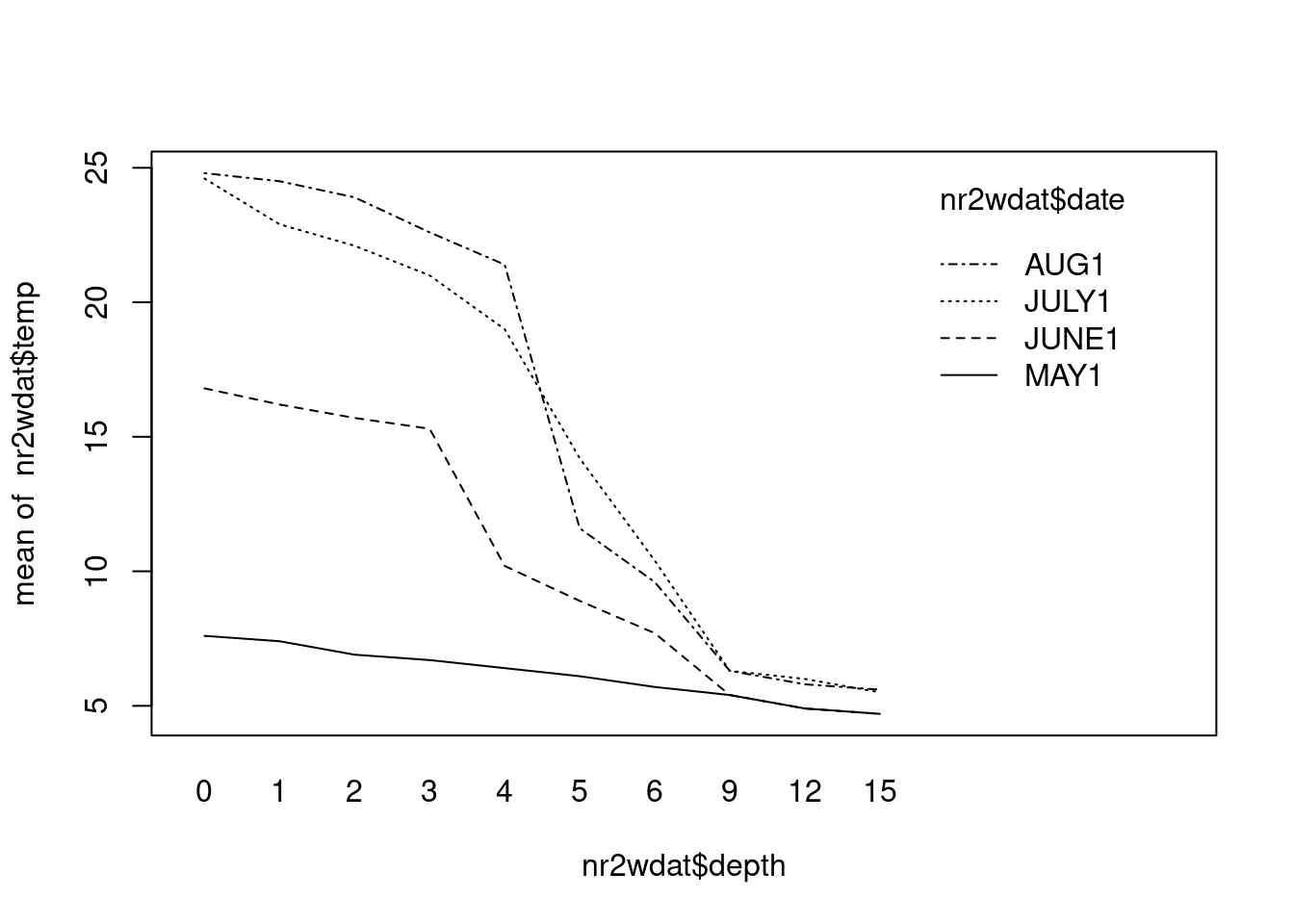
A limnologist studying Round Lake in Algonquin Park takes a single temperature ( temp ) reading at 10 different depths ( depth , in m) at four times ( date) over the course of the summer. Her data are shown in Nr2wdat.csv.
Do a two-way unreplicated ANOVA using temp as the dependent vari able, date and depth as the factor variables (you will need to recode depth to tell R to treat this variable as a factor). Note that there is no interaction term included in this model.
nr2wdat<-read.csv("data/nr2wdat.csv")nr2wdat$depth<-as.factor(nr2wdat$depth)anova.model4<-lm(temp~date+depth, data =nr2wdat)Anova(anova.model4, type =3)
Anova Table (Type III tests)
Response: temp
Sum Sq Df F value Pr(>F)
(Intercept) 1511.99 1 125.5652 1.170e-11 ***
date 591.15 3 16.3641 2.935e-06 ***
depth 1082.82 9 9.9916 1.450e-06 ***
Residuals 325.12 27
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Assuming that this is a Model III ANOVA ( date random, depth fixed), what do you conclude? (Hint: you may want to generate an interaction plot of temp versus depth and month, just to see what’s going on.)
Effet du mois et de la profondeur sur la température
There is a highly significant decrease in temperature as depth increases. To test the effect of month (the (assumed) random factor), we must assume that there is no interaction between depth and month, i.e. that the change in temperature with depth is the same for each month. This is a dubious assumption: if you plot temperature against depth for each month, you should see that the temperature profile becomes increasingly non-linear as the summer progresses (i.e. the thermocline develops), from almost a linear decline in early spring to what amounts to a step decline in August. In other words, the relationship between temperature and depth does change with month, so that if you were to use the above fitted model to estimate, say, the temperature at a depth of 5 m in July, you would not get a particularly good estimate.
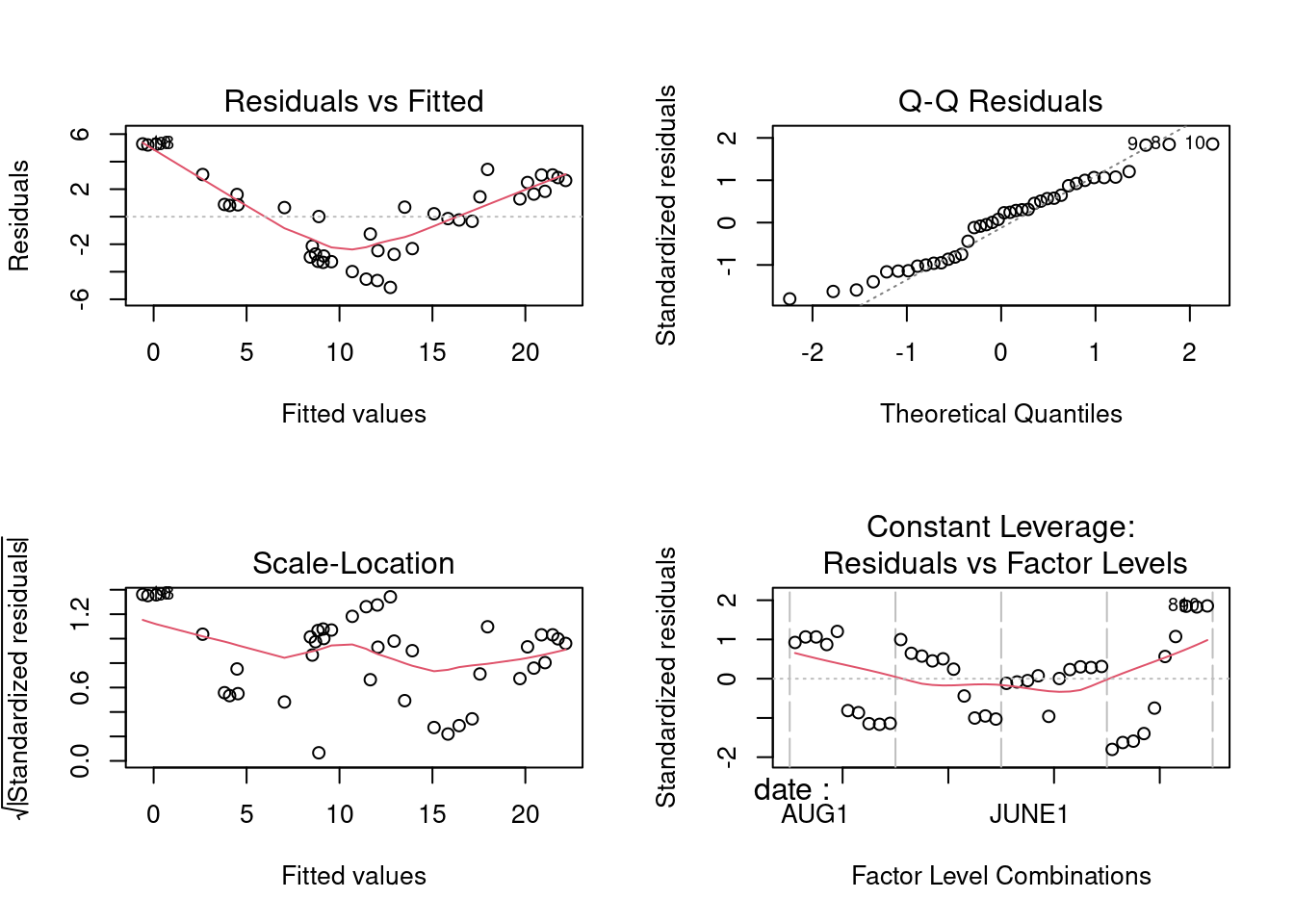
In terms of residual diagnostics, have a look at the residuals probability plot and residuals vs fitted values plot.
Shapiro-Wilk normality test
data: residuals(anova.model4)
W = 0.95968, p-value = 0.1634
Testing the residuals for normality, we get p = 0.16, so that the normality assumption seems to be O.K. In terms of heteroscedasticity, we can only test among months, using depths as replicates (or among depths using months as replicates). Using depths as replicates within months, we find
Warning in leveneTest.default(y = y, group = group, ...): group coerced to
factor.
Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 3 17.979 2.679e-07 ***
36
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
So there seems to be some problem here, as can be plainly seen in the above plot of residuals vs fit. All in all, this analysis is not very satisfactory: there appears to be some problems with the assumptions, and the assumption of no interaction between depth and date would appear to be invalid.
12.4 Nested designs
A common experimental design occurs when each major group (or treatment) is divided into randomly chosen subgroups. For example, a geneticist interested in the effects of genotype on desiccation resistance in fruit flies might conduct an experiment with larvae of three different genotypes. For each genotype (major group), she sets up three environmental chambers (sub-groups, replicates within groups) with a fixed temperature humidity regime, and in each chamber, she has five larvae for which she records the number of hours each larvae survived.
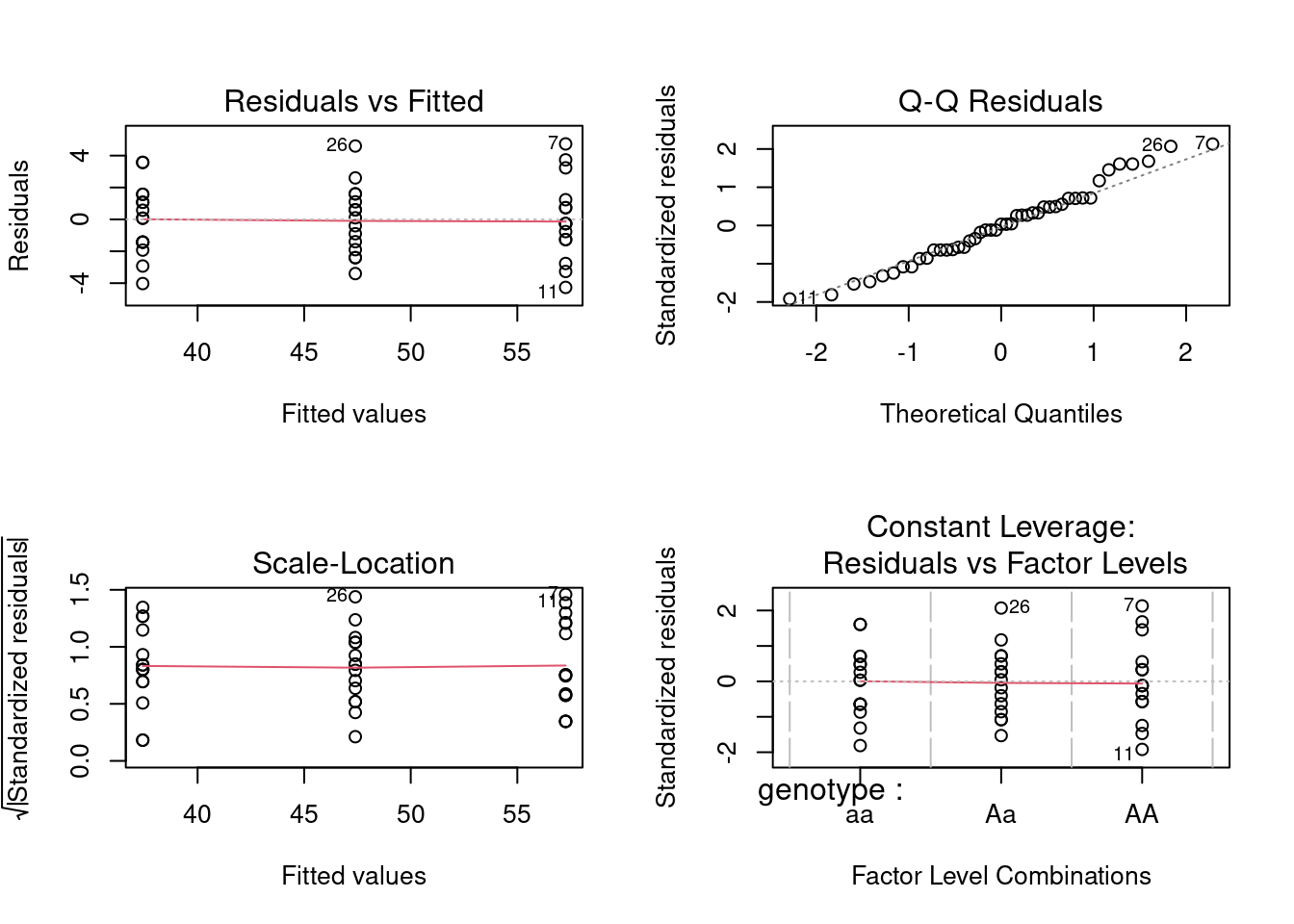
The file Nestdat.csv contains the results of just such an experi ment. The file lists three variables: genotype , chamber and survival . Run a nested ANOVA with survival as the dependent variable, genotype/chamber as the independent variables (this is the shorthand notation for a chamber effect nested under genotype).
nestdat<-read.csv("data/nestdat.csv")nestdat$chamber<-as.factor(nestdat$chamber)nestdat$genotype<-as.factor(nestdat$genotype)anova.nested<-lm(survival~genotype/chamber, data =nestdat)
What do you conclude from this analysis? What analysis would (should) you do next? (Hint: if there is a non-significant effect of chambers within genotypes, then you can increase the power of between-genotype comparisons by pooling over chambers within genotypes, although not everyone (Dr. Rundle included) agrees with such pooling.) Do it! Make sure you check your assumptions!
We conclude from this analysis that there is no (significant) variation among chambers within genotypes, but that the null hypothesis that all genotypes have the same dessiccation resistance (as measured by survival) is rejected (Test of genotype using MS genotype:chamber as denominator: F = 1476.11/6.78 = 217.7153, P<0.0001). In other words, genotypes differ in their survival.
Since the chambers within genotypes effect is non-significant, we may want to pool over chambers to increase our degrees of freedom:
anova.simple<-lm(survival~genotype, data =nestdat)anova(anova.simple)
Analysis of Variance Table
Response: survival
Df Sum Sq Mean Sq F value Pr(>F)
genotype 2 2952.22 1476.11 278.93 < 2.2e-16 ***
Residuals 42 222.26 5.29
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Thus, we conclude that there is significant variation among the three genotypes in dessiccation resistance.
A box plot of survival across genotypes shows clearly that there is significant variation among the three genotypes in dessiccation resistance. This can be combined with a formal Tukey multiple comparison test:
par(mfrow =c(1, 1))# Compute and plot means and Tukey CImeans<-glht(anova.simple, linfct =mcp( genotype ="Tukey"))cimeans<-cld(means)# use sufficiently large upper marginold.par<-par(mai =c(1, 1, 1.25, 1))# plotplot(cimeans, las =1)# las option to put y-axis labels as God intended them
Effet du genotype sur la résistance à la dessication avec un test de Tukey
So, we conclude from the Tukey analysis and plot that dessiccation resistance (R) , as measured by larval survival under hot, dry conditions, varies significantly among all three genotypes with R(AA) > R(Aa) > R(aa).
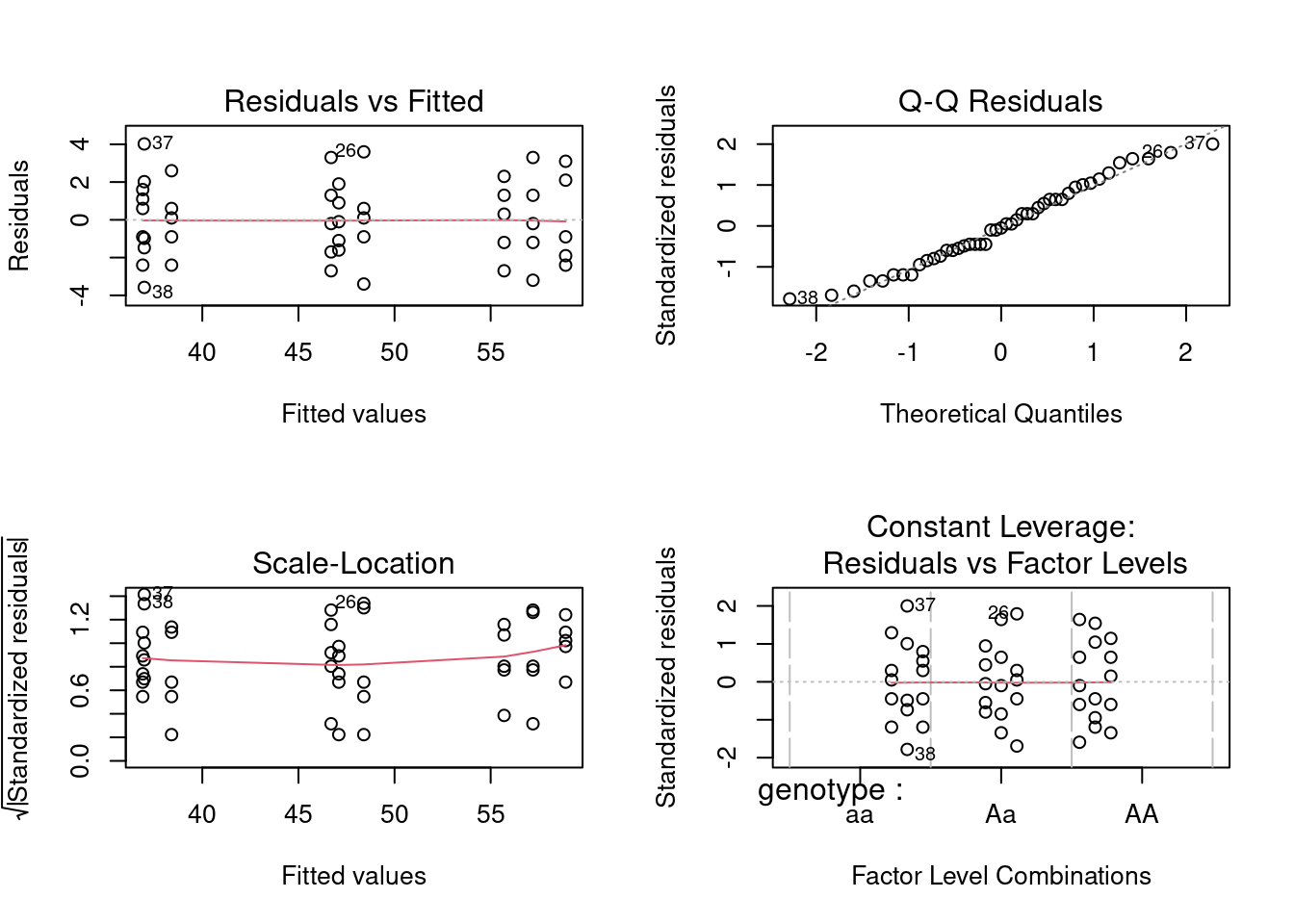
Before concluding this, however, we must test the assumptions. Here are the residual plots and diagnostics for the one-way (unnested) design:
So, all the assumptions appear to be valid, and the conclusion reached above still holds. Note that if you compare the residual mean squares of the nested and one-way ANOVAs (5.04 vs 5.29), they are almost identical. This is not surprising, given the small contribution of the chamber %in% genotype effect to the explained sum of squares.
12.5 Two-way non-parametric ANOVA
Two-way non-parametric ANOVA is an extension of the non-parametric one-way methods discussed previously. The basic procedure is to rank all the data in the sample from smallest to largest, then carry out a 2-way ANOVA on the ranks. This can be done either for replicated or unreplicated data.
Using the data file Stu2wdat.csv , do a two-factor ANOVA to examine the effects of sex and location on rank(rdwght).
aov.rank<-aov(rank(rdwght)~sex*location, contrasts =list( sex =contr.sum, location =contr.sum), data =Stu2wdat)
The Scheirer-Ray-Hare extension of the Kruskall-Wallis test is done by computing a statistic H given by the effect sums of squares (SS) divided by the total MS. The latter can be calculated as the variance of the ranks. We compute an H statistic for each term. The H-statistics are then compared to a theoretical \(\chi^2\) (chi-square) distribution using the command line: pchisq(H, df, lower.tail = FALSE) , where H and df are the calculated H-statistics and associated degrees of freedom, respectively.
Use the ANOVA table based on ranks to test the effects of sex and on rdwght. What do you conclude? How does this result compare with the result obtained with the parametric 2-way ANOVA done before?
To calculate the Scheirer-Ray-Hare extension to the Kruskall-Wallis test, you must first calculate the total mean square (MS), i.e. the variance of the ranked data. In this case, there are 186 observations, their ranks are therefore the series 1, 2, 3, …, 186. The variance can be calculated simply as var(1:186) (Isn’t R neat? Cryptic maybe, but neat). So we can compute the H statistic for each term:
Note that these results are the same as those obtained in our original two-way parametric ANOVA. Despite the reduced power, we still find significant differences between the sexes, but still no interaction and no effect due to location.
There is, however, an important difference. Recall that in the original parametric ANOVA, there was a significant effect of sex when we considered the problem as a Model I ANOVA. However, if we consider it as Model III, the significant sex effect could in principle disappear, because the df associated with the interaction MS are much smaller than the df associated with the Model I error MS. In this case, however, the interaction MS is about half that of the error MS. So, the significant sex effect becomes even more significant if we analyze the problem as a Model III ANOVA. Once again, we see the importance of specifying the appropriate ANOVA design.
12.6 Multiple comparisons
Further hypothesis testing in multiway ANOVAs depends critically on the outcome of the initial ANOVA. If you are interested in comparing groups of marginal means (that is, means of treatments for one factor pooled over levels of the other factor, e.g., between male and female sturgeon pooled over location), this can be done exactly as outlined for multiple comparisons for one-way ANOVAs. For comparison of individual cell means, you must specify the interaction as the group variable.
The file wmcdat2.csv shows measured oxygen consumption ( o2cons ) of two species ( species = A, B)) of limpets at three different concentrations of seawater ( conc = 100, 75, 50%) taken from Sokal and Rohlf, 1995, p. 332.
Run a 2-way factorial ANOVA on wmcdat2 data, using o2cons as the dependent variable and species and conc as the factors. What do you conclude?
TipSolution
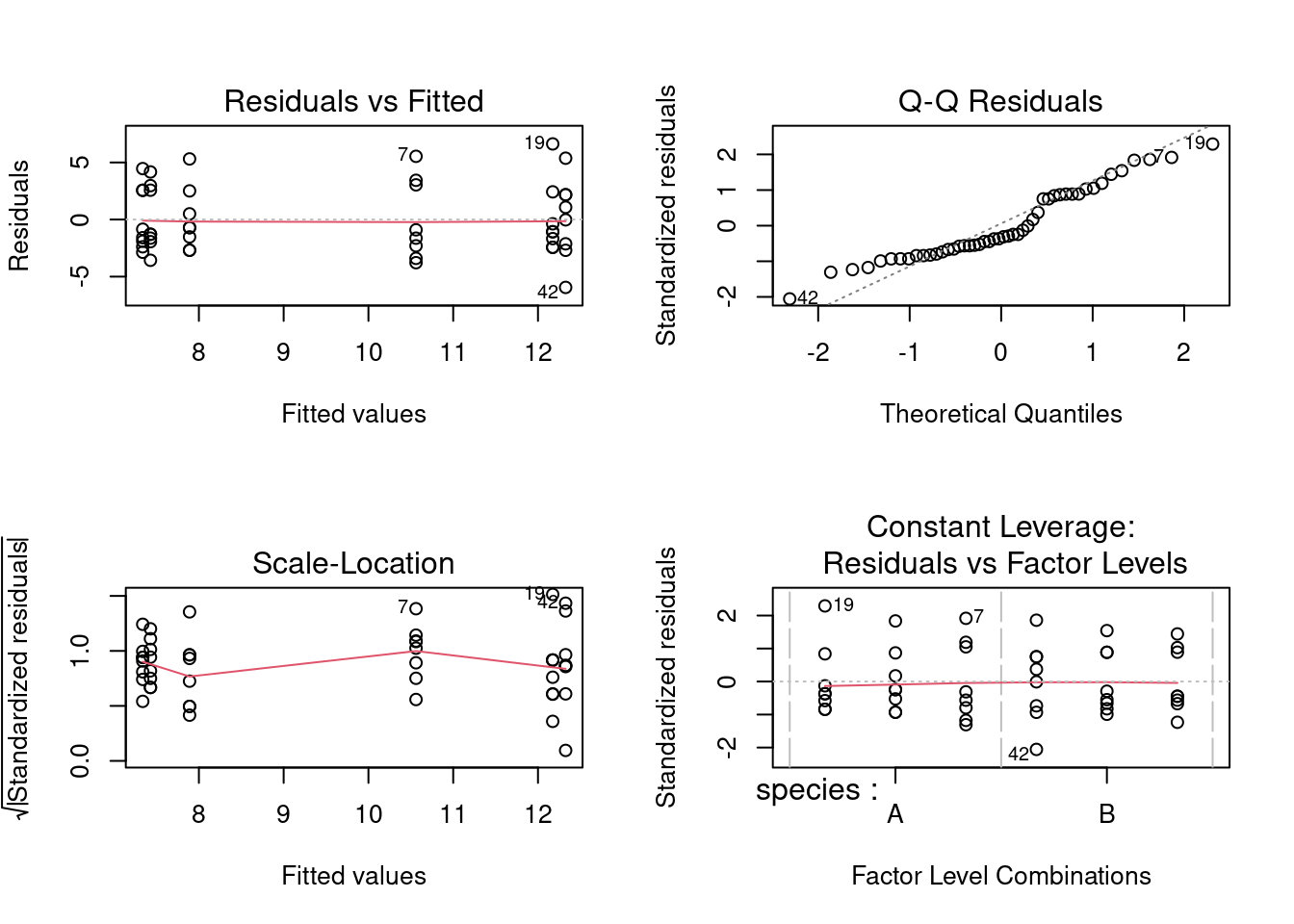
wmcdat2<-read.csv("data/wmcdat2.csv")wmcdat2$species<-as.factor(wmcdat2$species)wmcdat2$conc<-as.factor(wmcdat2$conc)anova.model5<-lm(o2cons~species*conc, data =wmcdat2)Anova(anova.model5, type =3)
The ANOVA table is shown below. Technically, because the sample sizes in individual cells are rather small, this analysis should be repeated using a non-parametric ANOVA. For the moment, let’s stick with the parametric analysis.
Shapiro-Wilk normality test
data: residuals(anova.model5)
W = 0.93692, p-value = 0.01238
So there is evidence of non-normality, but otherwise everything looks O.K. Since the ANOVA is relatively robust with respect to non-normality, we proceed, but if we wanted to reassure ourselves, we could run a non-parametric ANOVA, and get the same answer.
On the basis of the ANOVA results obtained above, which means would you proceed to compare? Why?
TipSolution
Need to add an explnation here
Overall, we conclude that there are no differences among species, and that the effect of concentration does not depend on species (no interaction). Since there is no interaction and no main effect due to species, the only comparison of interest is among salinity concentrations:
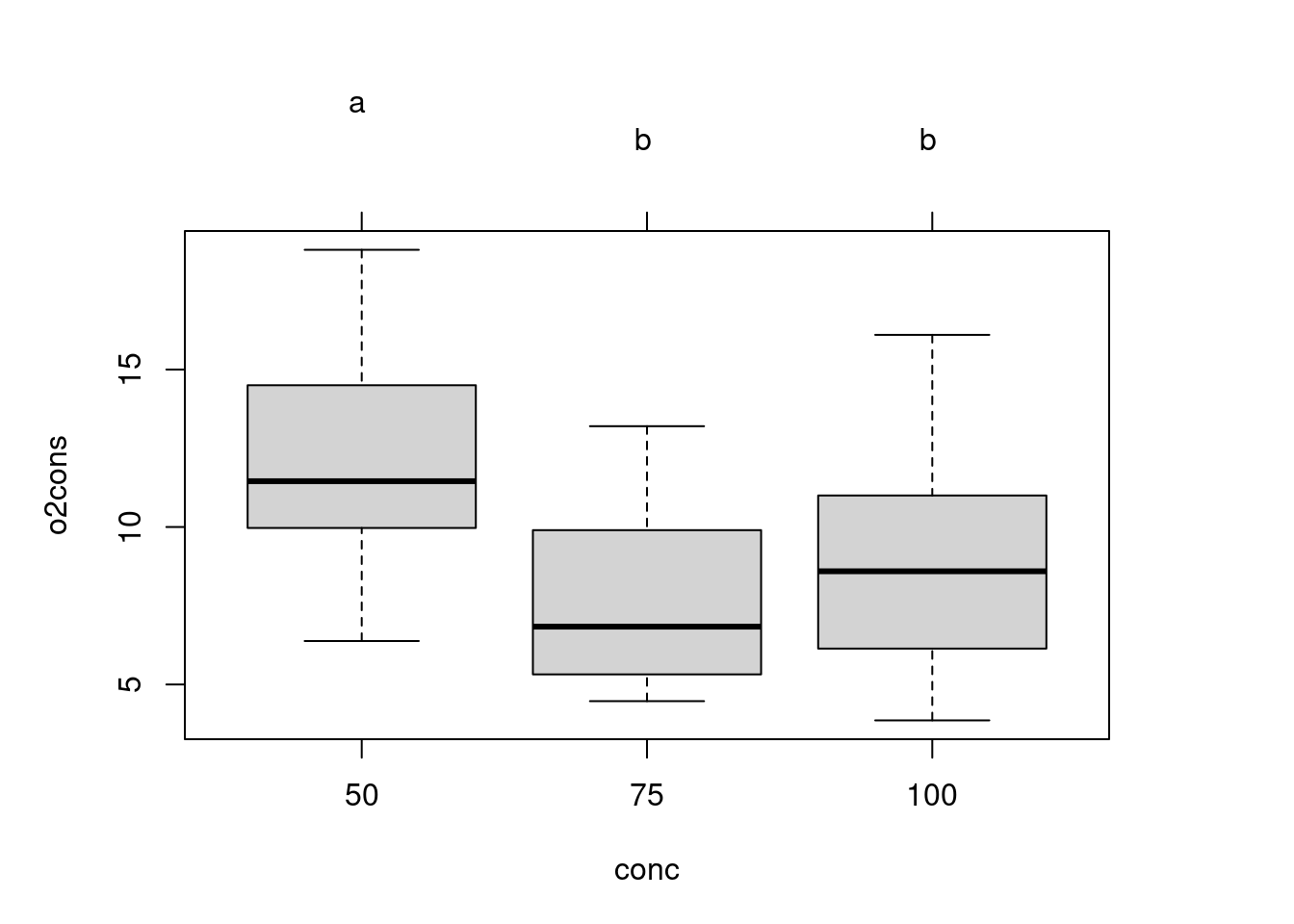
# fit simplified modelanova.model6<-aov(o2cons~conc, data =wmcdat2)# Make Tukey multiple comparisonsTukeyHSD(anova.model6)
Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = o2cons ~ conc, data = wmcdat2)
$conc
diff lwr upr p adj
75-50 -4.63625 -7.321998 -1.9505018 0.0003793
100-50 -3.25500 -5.940748 -0.5692518 0.0141313
100-75 1.38125 -1.304498 4.0669982 0.4325855
par(mfrow =c(1, 1))# Graph of all comparisons for conctuk<-glht(anova.model6, linfct =mcp(conc ="Tukey"))# extract informationtuk.cld<-cld(tuk)# use sufficiently large upper marginold.par<-par(mai =c(1, 1, 1.25, 1))# plotplot(tuk.cld)
Comparaison de Tukey des moyennes de consommation d’oxygèn en fonction del la concentration
So there is evidence of a significant difference in oxygen consumption at a reduction in salinity to 50% of regular seawater, but not at a reduction of only 25%.
Repeat the analysis described above using wmc2dat2.csv . How do your results compare with those obtained for wmcdat2.csv ?
TipSolution
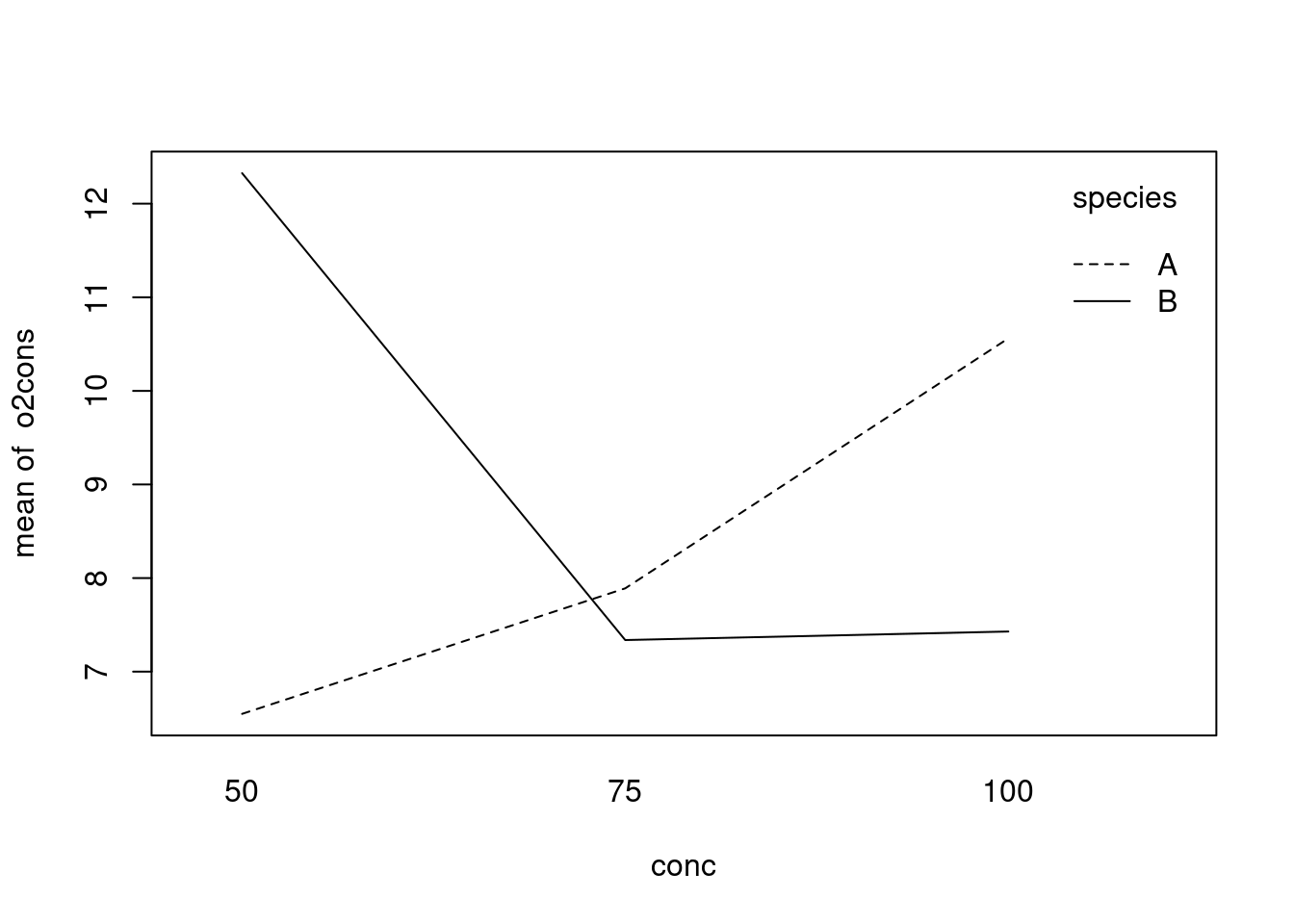
wmc2dat2<-read.csv("data/wmc2dat2.csv")wmc2dat2$species<-as.factor(wmc2dat2$species)wmc2dat2$conc<-as.factor(wmc2dat2$conc)anova.model7<-lm(o2cons~species*conc, data =wmc2dat2)
Here there is a large interaction effect, and consequently, there is no point in comparing marginal means. This is made clear by examining an interaction plot:
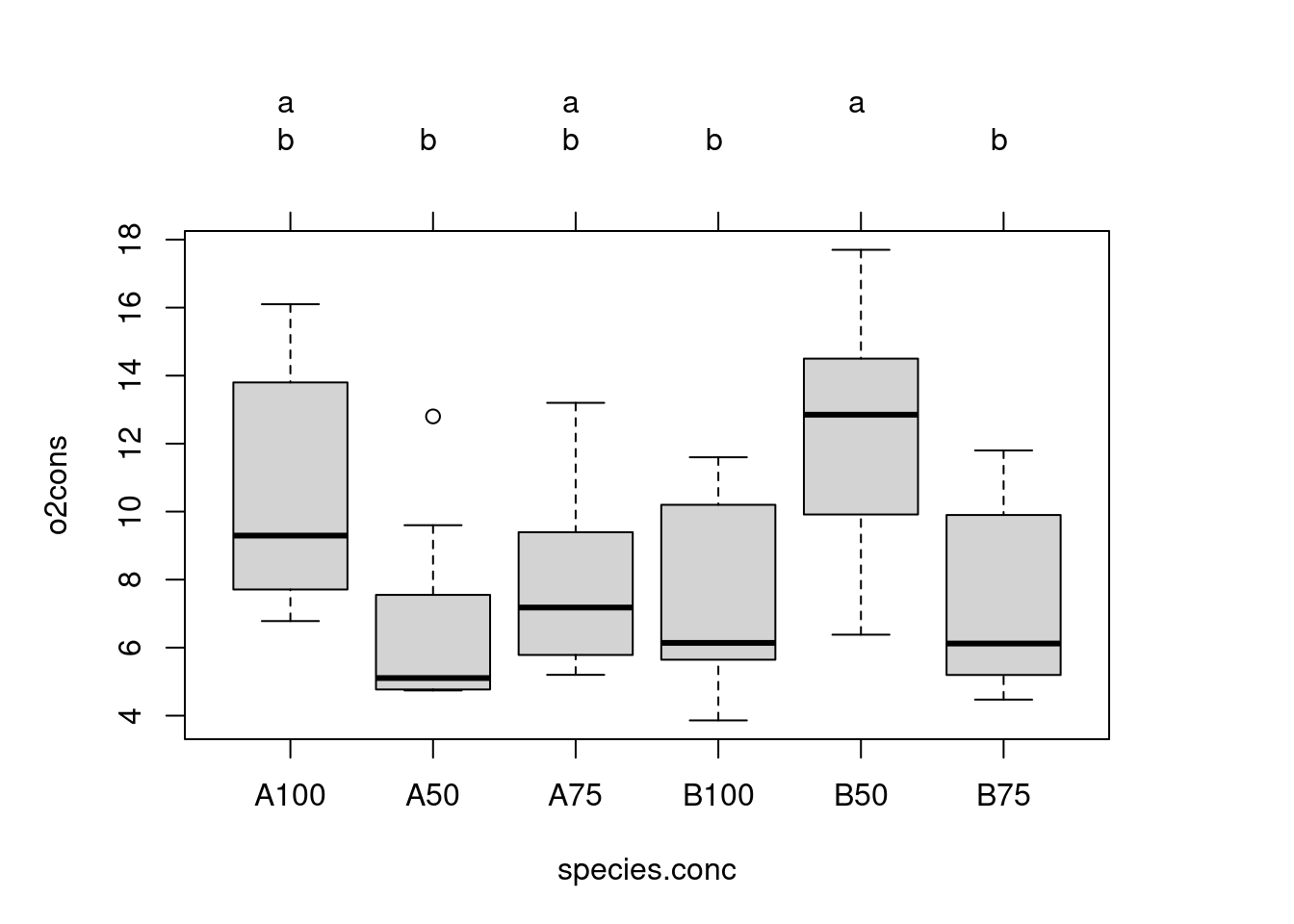
Working still with the wmc2dat2 data set, compare individual cell means (6 in all), with the Bonferonni adjustment. To do this, it is helpful to create a new variable to indicate all the combinations of species and conc:
Pairwise comparisons using t tests with pooled SD
data: o2cons and species.conc
A100 A50 A75 B100 B50
A50 0.1887 - - - -
A75 1.0000 1.0000 - - -
B100 0.7223 1.0000 1.0000 - -
B50 1.0000 0.0079 0.0929 0.0412 -
B75 0.6340 1.0000 1.0000 1.0000 0.0350
P value adjustment method: bonferroni
These comparisons are a little more difficult to interpret, but the analysis essentially examines for differences among seawater concentrations within species A and for differences among concentrations within species B. We see here that the o2Cons at 50% seawater for species B is significantly different from that of 75% and 100% seawater for species B, whereas there are no significant differences in o2cons for species A across all seawater concentrations.
I find these outputs rather unsatisfying because they show only p-values, but no indication of effect size. One can get both the conclusion from the multiple comparison procedure and an indication of effect size from the graph produced with the following code:
# fit one-way anova comparing all combinations of species.conc combinationsanova.modelx<-aov(o2cons~species.conc, data =wmc2dat2)tuk2<-glht(anova.modelx, linfct =mcp(species.conc ="Tukey"))# extract informationtuk2.cld<-cld(tuk2)# use sufficiently large upper marginold.par<-par(mai =c(1, 1, 1.25, 1))# plotplot(tuk2.cld)
Note that in this analysis, we have used the error MS = 9.474 from the original model to contrast cell means. Recall, however, that this assumes that in fact we are dealing with a Model I ANOVA, which may or may not be the case ( conc is certainly a fixed factor, but species might be either fixed or random).
12.7 Test de permutation pour l’ANOVA à deux facteurs de classification
When data do not meet the assumptions of the parametric analysis in two- and multiway ANOVA, as an alternative to the non-parametric ANOVA, it is possible to run permutation tests to calculate p-values. The lmPerm package does this easily.
######################################################################### lmPerm version of permutation testlibrary(lmPerm)# for generality, copy desired dataframe to mydata# and model formula to myformulamydata<-Stu2wdatmyformula<-as.formula("rdwght ~ sex+location+sex:location")# Fit desired model on the desired dataframemymodel<-lm(myformula, data =mydata)# Calculate permutation p-valueanova(lmp(myformula, data =mydata, perm ="Prob", center =FALSE, Ca =0.001))
lmPerm was orphaned for a while and the code below, while clunkier, provided an alternative way of doing it. You would have to adapt it for other situations.
############################################################ Permutation test for two way ANOVA# Ter Braak creates residuals from cell means and then permutes across# all cells# This can be accomplished by taking residuals from the full model# modified from code written by David C. Howell# http://www.uvm.edu/~dhowell/StatPages/More_Stuff/Permutation%20Anova/PermTestsAnova.htmlnreps<-500dependent<-Stu2wdat$rdwghtfactor1<-as.factor(Stu2wdat$sex)factor2<-as.factor(Stu2wdat$location)my.dataframe<-data.frame(dependent, factor1, factor2)my.dataframe.noNA<-my.dataframe[complete.cases(my.dataframe), ]mod<-lm(dependent~factor1+factor2+factor1:factor2, data =my.dataframe.noNA)res<-mod$residualsTBint<-numeric(nreps)TB1<-numeric(nreps)TB2<-numeric(nreps)ANOVA<-summary(aov(mod))cat(" The standard ANOVA for these data follows ","\n")F1<-ANOVA[[1]]$"F value"[1]F2<-ANOVA[[1]]$"F value"[2]Finteract<-ANOVA[[1]]$"F value"[3]print(ANOVA)cat("\n")cat("\n")TBint[1]<-Finteractfor(iin2:nreps){newdat<-sample(res, length(res), replace =FALSE)modb<-summary(aov(newdat~factor1+factor2+factor1:factor2, data =my.dataframe.noNA))TBint[i]<-modb[[1]]$"F value"[3]TB1[i]<-modb[[1]]$"F value"[1]TB2[i]<-modb[[1]]$"F value"[2]}probInt<-length(TBint[TBint>=Finteract])/nrepsprob1<-length(TB1[TB1>=F1])/nrepsprob2<-length(TB2[TB1>=F2])/nrepscat("\n")cat("\n")print("Resampling as in ter Braak with unrestricted samplingof cell residuals. ")cat("The probability for the effect of Interaction is ",probInt, "\n")cat("The probability for the effect of Factor 1 is ",prob1, "\n")cat("The probability for the effect of Factor 2 is ",prob2, "\n")
12.8 Bootstrap for two-way ANOVA
In most cases, permutation tests will be more appropriate than bootstrap in ANOVA designs. However, for the sake of completedness, I have a snippet of code to do bootstrap for you::
######################################################################## Bootstrap for two-way ANOVA# You possibly want to edit bootfunction.mod1 to return other values# Here it returns the standard coefficients of the fitted model# Requires boot library#nreps<-5000dependent<-Stu2wdat$rdwghtfactor1<-as.factor(Stu2wdat$sex)factor2<-as.factor(Stu2wdat$location)my.dataframe<-data.frame(dependent, factor1, factor2)my.dataframe.noNA<-my.dataframe[complete.cases(my.dataframe), ]library(boot)# Fit model on observed datamod1<-aov(dependent~factor1+factor2+factor1:factor2, data =my.dataframe.noNA)# Bootstrap 1000 time using the residuals bootstraping methods to# keep the same unequal number of observations for each level of the indep. var.fit<-fitted(mod1)e<-residuals(mod1)X<-model.matrix(mod1)bootfunction.mod1<-function(data, indices){y<-fit+e[indices]bootmod<-lm(y~X)coefficients(bootmod)}bootresults<-boot(my.dataframe.noNA, bootfunction.mod1, R =1000)bootresults## Calculate 90% CI and plot bootstrap estimates separately for each model parameterboot.ci(bootresults, conf =0.9, index =1)plot(bootresults, index =1)boot.ci(bootresults, conf =0.9, index =3)plot(bootresults, index =3)boot.ci(bootresults, conf =0.9, index =4)plot(bootresults, index =4)boot.ci(bootresults, conf =0.9, index =5)plot(bootresults, index =5)