Utiliser R pour faire une analyse de covariance (ANCOVA) et ajuster des modèles ayant des variables indépendantes continues et discontinues (modèle linéaire général)
Utiliser R pour vérifier les conditions préalables à ces modèles
Utiliser R pour comparer l’ajustement de modèles statistiques
Utiliser R pour faire des tests de bootstrap et de permutation sur des modèles avec des variables indépendantes continues et discontinues.
14.1 Paquets et données requises pour le labo
Pour ce laboratoire, vous aurez besoin de :
Paquets R :
ggplot2📦
car📦
lmtest📦
Jeux de données :
“anc1dat.csv”
“anc3dat.csv”
14.2 Modèle linéaire général
Les modèles linéaires généraux ou “General Linear Model” en anglais sont différent des modèles linéaires généralisés (ou “Generalized Linear Model”, GLM).
Les modèles linéaires généraux sont des modèles statistiques de la forme \(Y = B \mathbf{X} + E\), ou
Y est un vecteur contenant la variable dépendante continue,
B est un vecteur des paramètres estimés,
\(\mathbf{X}\) et la matrice des différents variables indépendantes et
E est un vecteur de résidus homoscédastiques et normalement distribués.
Tous les tests que nous avons étudiés jusque là (test de t, régression linéaire simple, ANOVA à un facteur de classification, ANOVA à plusieurs facteurs de classification et régression multiple) sont formulés ainsi. Notez que tous les modèles que nous avons rencontrés à ce jour ne contiennent qu’un type de variable indépendante : soit continue (numérique) ou discontinue (catégorique). Dans cet exercice de laboratoire, vous allez ajuster des modèles qui ont les deux types de variables indépendantes.
14.3 ANCOVA
ANCOVA est l’abréviation pour l’analyse de covariance. C’est un type de modèle linéaire général dans lequel il y a une (ou plusieurs) variable indépendante continue (parfois appelé la covariable) et une (ou plusieurs) variable indépendante discontinue (catégorique). Dans la présentation traditionnelle de l’ANCOVA dans les manuels de biostatistique, le modèle ANCOVA ne contient pas de termes d’interaction entre les variables continues et discontinues. Par conséquent, on doit précéder l’ajustement de ce modèle (réduit parce que sans terme d’interaction), par un test de signification de l’interaction qui correspond à éprouver l’égalité des pentes (coefficients pour la ou les variables continues) entre les différents niveaux de la ou des variables discontinues (i.e un test d’homogénéité des pentes).
14.4 Homogénéité des pentes
Pour répondre à de nombreuses questions biologiques, il est nécessaire de déterminer si deux (ou plus) régressions diffèrent significativement. Par exemple, pour comparer l’efficacité de deux insecticides on doit comparer la relation entre leur dose et la mortalité. Ou encore, pour comparer le taux de croissance des mâles et des femelles on doit comparer la relation entre la taille et l’âge des mâles et des femelles.
Comme chaque régression linéaire est décrite par deux paramètres, la pente et l’ordonnée à l’origine, on doit considérer les deux dans la comparaison. Le modèle d’ANCOVA, à strictement parler, n’éprouve que l’hypothèse d’égalité des ordonnées à l’origine. Cependant, avant d’ajuster ce modèle, il faut éprouver l’hypothèse d’égalité des pentes (homogénéité des pentes).
14.4.1 Cas 1 - La taille en fonction de l’âge (exemple avec pente commune)
Exercice
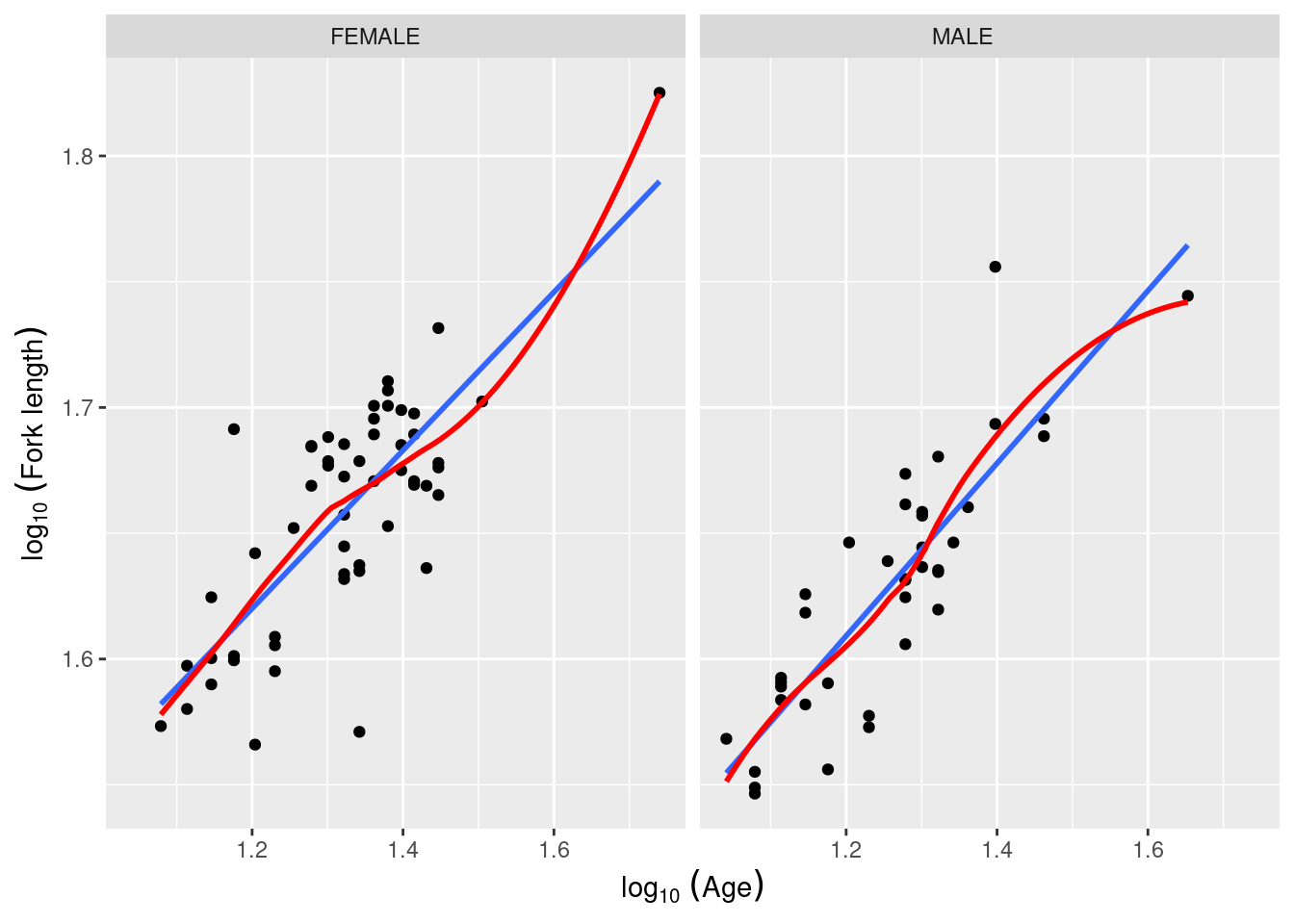
En utilisant les données du fichier anc1dat.csv, éprouvez l’hypothèse que le taux de croissance des esturgeons mâles et femelles de The Pas est le même (données de 1978-1980). Comme mesure du taux de croissance, nous allons utiliser la pente de la régression du log 10 de la longueur à la fourche, lfkl, sur le log 10 de l’age.
Commençons par examiner les données. Pour faciliter la comparaison, il serait utile de tracer la droite de régression et la trace “lowess” pour évaluer plus facilement la linéarité. On peut aussi ajouter un peu de code pour obtenir des légendes plus complètes (remarquez l’utilisation de la commande expression() pour obtenir des indices) :
anc1dat<-read.csv("data/anc1dat.csv")anc1dat$sex<-as.factor(anc1dat$sex)myplot<-ggplot(data =anc1dat, aes(x=lage, y=log10(fklngth)))+facet_grid(.~sex)+geom_point()myplot<-myplot+geom_smooth(method =lm, se=FALSE)+geom_smooth(se=FALSE, color="red")+labs( y =expression(log[10]~(Fork~length)), x =expression(log[10]~(Age)))myplot
Figure 14.1: Longueur des esturgeons en fonction de l’age entre mâles et femelles.
La transformation log-log rend la relation linéaire et, à première vue, il ne semble pas y avoir de problème évident avec les conditions d’application. Ajustons donc le modèle complet avec l’interaction:
model.full1<-lm(lfkl~sex+lage+sex:lage, data =anc1dat)Anova(model.full1, type =3)
Anova Table (Type III tests)
Response: lfkl
Sum Sq Df F value Pr(>F)
(Intercept) 0.64444 1 794.8182 < 2.2e-16 ***
sex 0.00041 1 0.5043 0.4795
lage 0.07259 1 89.5312 4.588e-15 ***
sex:lage 0.00027 1 0.3367 0.5632
Residuals 0.07135 88
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Notez que l’on utilise la fonction Anova() du paquet car📦 avec un “A” majuscule au lieu de la fonction native anova() (avec un “a” minuscule”) pour obtenir les sommes de carrés de type III (partiels). Ces sommes des carrés des écarts sont calculées comme si la variable était entrée la dernière dans le modèle et correspondent à la différence entre la variance expliquée par le modèle complet et par le modèle sans cette variable.
La fonction native anova() donne les sommes des carrés séquentielles, calculées au fur et à mesure que chaque variable est ajoutée au modèle nul avec seulement une ordonnée à l’origine. Dans de rares cas, les sommes des carrés de type I et III sont égales (quand le design est parfaitement orthogonal ou balancé). Dans la vaste majorité des cas, les sommes des carrés de type I et III sont différentes et je vous conseille de toujours utiliser les sommes des carrés de type III dans vos analyses.
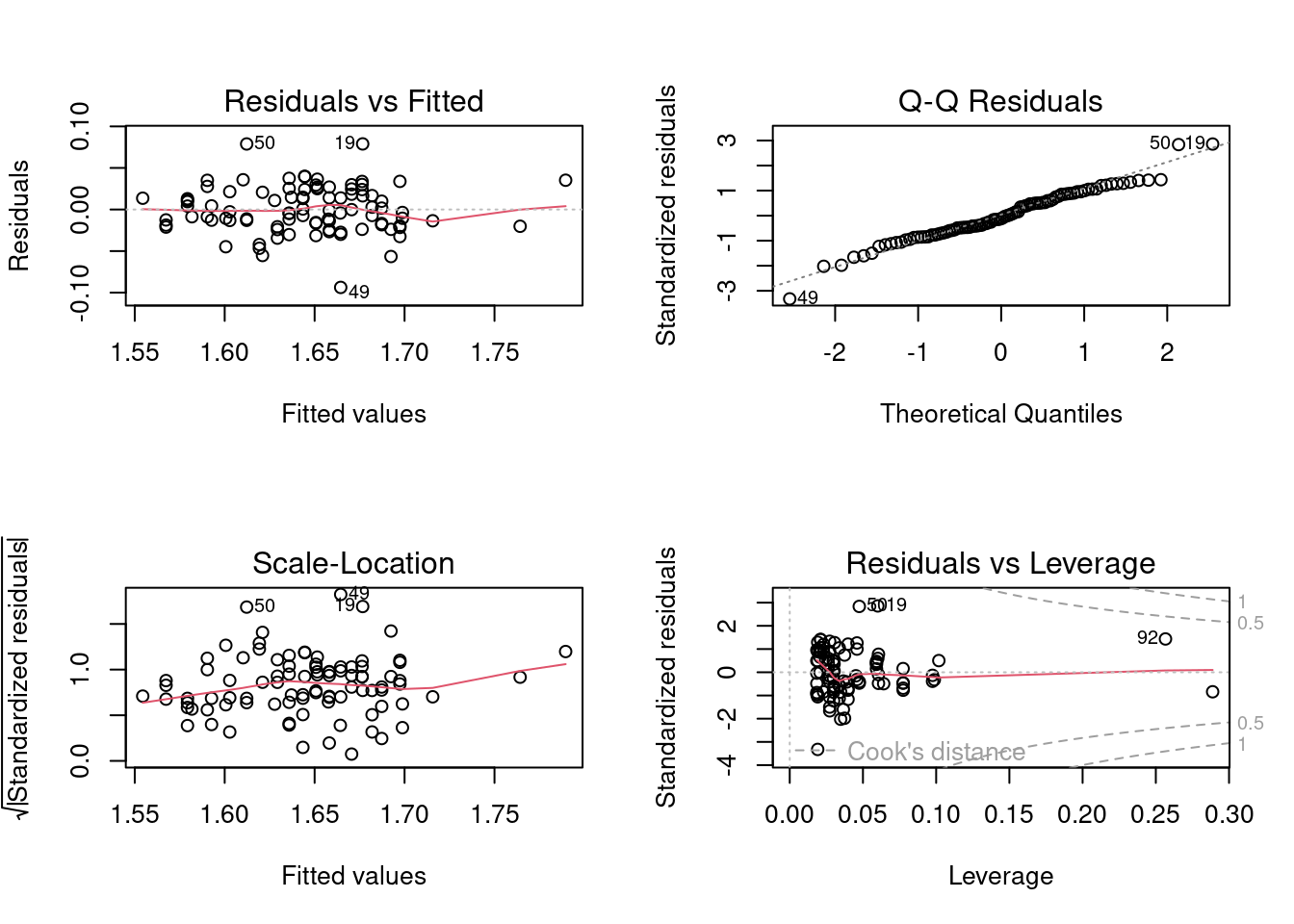
À partir de cette analyse, on devrait accepter les hypothèses nulles (1) d’égalité des pentes pour les deux sexes, et (2) que les ordonnées à l’origine sont les mêmes pour les deux sexes. Mais, avant d’accepter ces conclusions, il faut vérifier si les données rencontrent les conditions d’application, comme d’habitude…
Figure 14.2: Conditions d’applications du modèle model.full1
En ce qui concerne la normalité, ça a l’air d’aller quoiqu’il y a quelques points, en haut à droite, qui dévient. Si on effectue le test de Wilk-Shapiro (W = .9764, p = 0.09329), on confirme que les résidus ne dévient pas significativement de la normalité.
Les résidus semblent homoscédastiques, mais si vous voulez vous en assurer, vous pouvez l’éprouver par un des tests formels. Ici j’utilise le test Breusch-Pagan, qui est approprié quand certaines des variables indépendantes sont continues (Le test de Levene n’est approprié que lorsqu’il n’y a que des variables discontinues).
bptest(model.full1)
studentized Breusch-Pagan test
data: model.full1
BP = 0.99979, df = 3, p-value = 0.8013
Comme l’hypothèse nulle de ce test est que les résidus sont homoscédastiques, et que p est relativement élevé, le test confirme l’évaluation visuelle. De plus, il n’y a pas de tendance évidente dans les résidus, suggérant qu’il n’y a pas de problème de linéarité. Ce qui peut également être éprouvé formellement:
resettest(model.full1, power =2:3, type ="regressor", data =anc1dat)
La dernière condition d’application est qu’il n’y a pas d’erreur de mesure sur la variable indépendante continue. On ne peut pas vraiment éprouver cette condition, mais on sait que des estimés indépendants de l’âge des poissons obtenus par différents chercheurs donnent des âges qui concordent avec moins de 1-2 ans d’écart, ce qui est inférieur au 10% de la fourchette observée des âges et donc acceptable pour des analyses de modèles de type I (attention ici on ne parle pas des SC de type I, je sais, c’est facile de confondre…)
Vous noterez qu’il y a une observation qui a un résidu normalisé (Standardized residual) qui est élevé, i.e. une valeur extrême (cas numéro 49). Éliminez-la de l’ensemble de données et refaites l’analyse. Vos conclusions changent-elles?
model.full.no49<-lm(lfkl~sex+lage+sex:lage, data =anc1dat[c(-49),])Anova(model.full.no49, type=3)
Anova Table (Type III tests)
Response: lfkl
Sum Sq Df F value Pr(>F)
(Intercept) 0.64255 1 895.9394 <2e-16 ***
sex 0.00038 1 0.5273 0.4697
lage 0.07378 1 102.8746 <2e-16 ***
sex:lage 0.00022 1 0.3135 0.5770
Residuals 0.06239 87
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
La conclusion ne change pas après avoir enlevé la valeur extrême. Comme on n’a pas de bonne raison d’éliminer cette valeur, il est probablement mieux de la conserver. Un examen des conditions d’application après avoir enlevé cette valeur révèle qu’elles sont toutes rencontrées.
14.4.2 Cas 2 - Taille en fonction de l’âge (exemple avec des pentes différentes)
Exercice
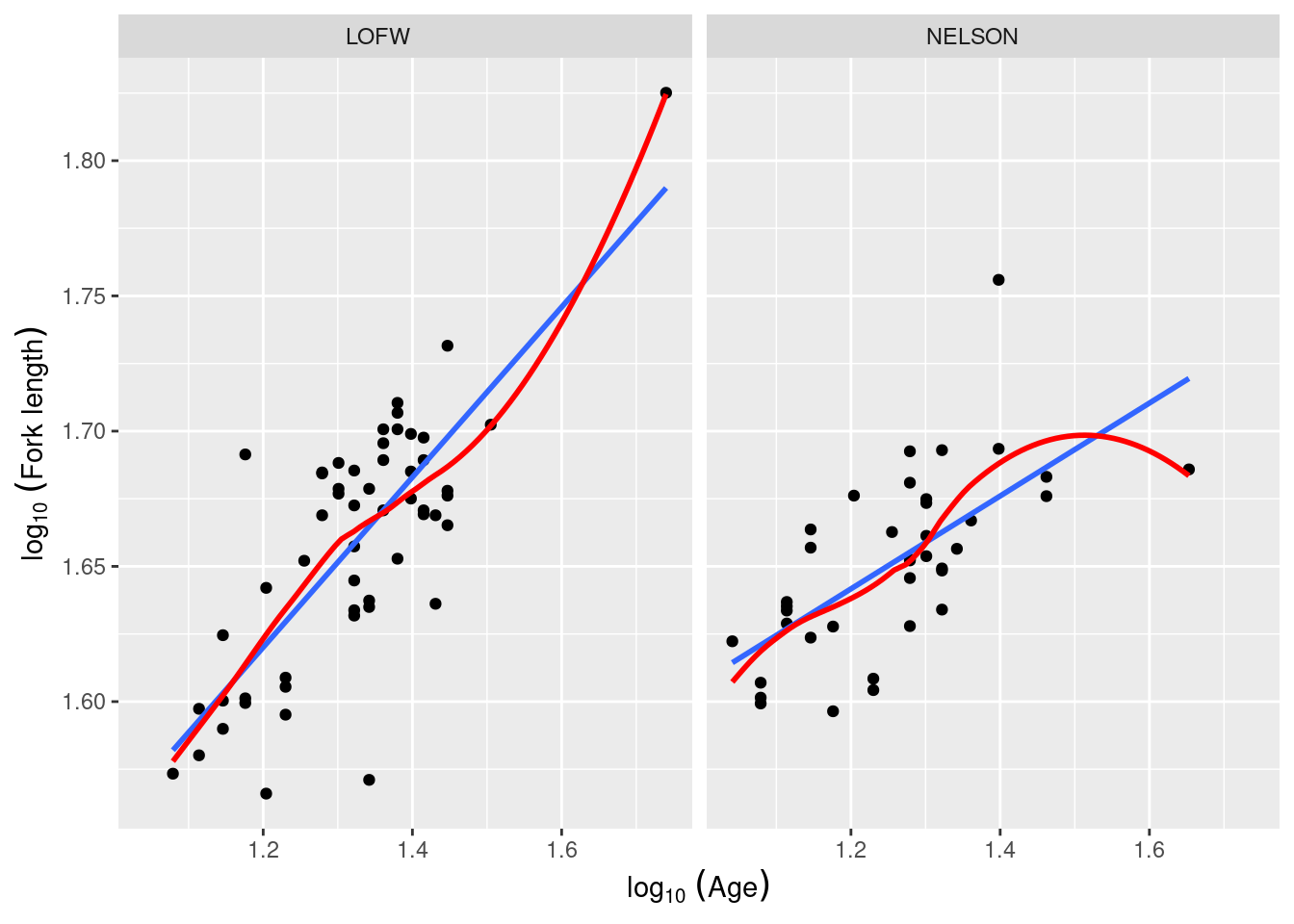
Le fichier anc3dat.csv contient des données sur des esturgeons mâles de deux sites (locate) : Lake of the Woods dans le Nord-Ouest de l’Ontario et Chruchill River dans le Nord du Manitoba. En utilisant la même procédure, éprouvez l’hypothèse que la pente de la régression de lfkl sur lage est la même aux deux sites (alors Locate est la variable catégorique au lieu de sex). Que concluez-vous?
anc3dat<-read.csv("data/anc3dat.csv")myplot<-ggplot(data =anc3dat, aes(x =lage, y =log10(fklngth)))+facet_grid(.~locate)+geom_point()+geom_smooth(method =lm, se =FALSE)+geom_smooth(se =FALSE, color ="red")+labs( y =expression(log[10]~(Fork~length)), x =expression(log[10]~(Age)))myplotmodel.full2<-lm(lfkl~lage+locate+lage:locate, data =anc3dat)Anova(model.full2, type =3)
Figure 14.3: Longueur des esturgeons en fonction de l’age selon le site d’étude d’après anc3dat.csv
Ici, on rejette les hypothèses nulles (1) que les pentes sont les mêmes dans les deux sites et (2) que les ordonnées à l’origine sont égales. En d’autres mots, si on veut prédire la longueur à la fourche d’un esturgeon à un âge donné précisément, il faut savoir de quel site il provient. Puisque les pentes diffèrent, il faut estimer des régressions séparées.
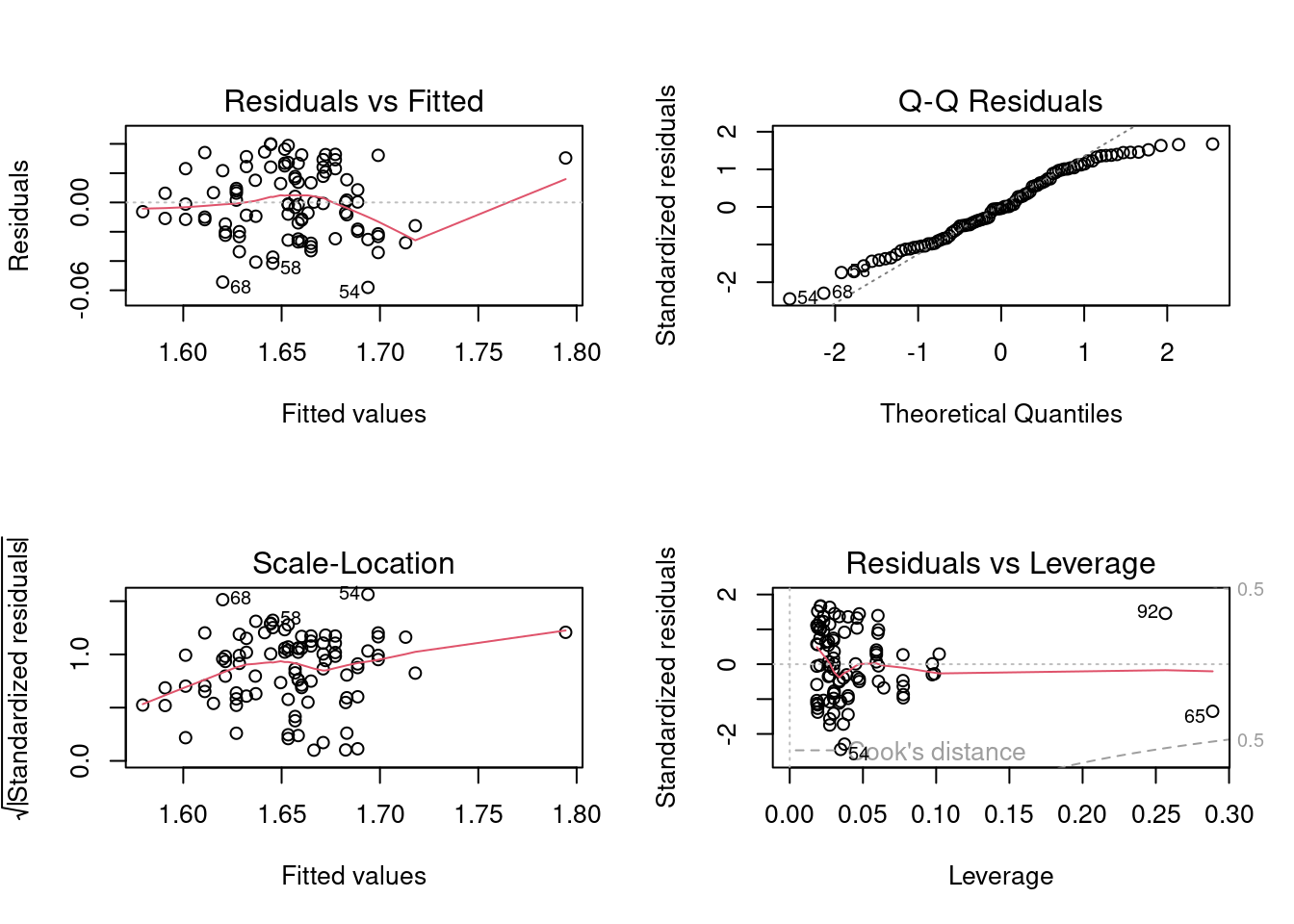
Mais avant d’accepter ces conclusions, on doit s’assurer que les conditions d’application sont rencontrées :
Figure 14.4: Conditions d’applications du modèle model.full2
Si on examine les résidus selon les méthodes habituelles, on voit qu’il n’y a pas de problème de linéarité, ni d’homoscédasticité (BP = 2.8721, p = 0.4118). Cependant, le test de Wilk-Shapiro est significatif (W=0.97, p = 0.03). Étant donné la taille assez grande de l’échantillon (N=92), ce test a beaucoup de puissance, même si la déviation de normalité ne semble pas très grande. Compte-tenu de la robustesse relative des LM, de la taille de l’échantillon, on ne s’inquiète pas trop de cette déviation de normalité.
Donc, comme les conditions des LM sont suffisamment remplies, on peut accepter les résultats donnés par R. Tous les termes sont significatifs (location, lage, interaction). Ce modèle complet est équivalent à ajuster des régressions séparées pour chaque site. Pour obtenir les coefficients, on peut ajuster des régressions simples sur chaque sous-ensemble, ou extraire les coefficients ajustés du modèle complet:
model.full2
Call:
lm(formula = lfkl ~ lage + locate + lage:locate, data = anc3dat)
Coefficients:
(Intercept) lage locateNELSON
1.2284 0.3253 0.2207
lage:locateNELSON
-0.1656
Par défaut, la variable locate est encodée comme 0 pour le site qui vient le premier en ordre alphabétique (LofW) et 1 pour l’autre (Nelson). Les régressions pour chaque site deviennent donc:
Pour LofW: \[\begin{aligned}
lfkl &= 1.2284 + 0.3253 \times lage + 0.2207 \times 0 - 0.1656 \times 0 \times lage \\
&= 1.2284 + 0.3253 \times lage
\end{aligned}\]
Pour Nelson: \[\begin{aligned}
lfkl &= 1.2284 + 0.3253 \times lage + 0.2207 \times 1 - 0.1656 \times 1 \times lage \\
&= 1.4491 + 0.1597 \times lage
\end{aligned}\]
Vous pouvez vérifier en ajustant séparément les régressions pour chaque site:
anc3dat$locate: LOFW
Call:
lm(formula = lfkl ~ lage, data = x)
Coefficients:
(Intercept) lage
1.2284 0.3253
------------------------------------------------------------
anc3dat$locate: NELSON
Call:
lm(formula = lfkl ~ lage, data = x)
Coefficients:
(Intercept) lage
1.4491 0.1597
14.5 Le modèle d’ANCOVA
Si le test d’homogénéité des pentes indique qu’elles diffèrent, alors on devrait estimer des régressions individuelles pour chaque niveau des variables discontinues.
Cependant, si on accepte l’hypothèse d’égalité des pentes, l’étape suivante est de comparer les ordonnées à l’origine. Selon la méthode traditionnelle i.e., on ajuste un modèle avec la variable catégorique et la variable continue, mais sans interaction (le modèle ANCOVA sensus stricto) et on utilise la somme des carrés des écarts de type III, avec la fonction Anova().
L’autre approche consiste à utiliser les résultats de l’analyse du modèle complet, et tester la signification de chaque terme à partir des sommes des carrés partiels. C’est plus rapide, mais moins puissant. Dans la plupart des cas, cette perte de puissance n’est pas trop préoccupante, sauf lorsque le modèle est très complexe et contient de nombreuses interactions non-significatives. Je vous suggère d’utiliser l’approche simplifiée, et de n’utiliser l’approche traditionnelle que lorsque vous acceptez l’hypothèse d’égalité des ordonnées à l’origine. Pourquoi?
Puisque l’approche simplifiée est moins puissante, si vous rejetez quand même H0, alors votre conclusion ne changera pas, mais sera seulement renforcée, en utilisant l’approche traditionnelle.
Ici, je vais comparer l’approche traditionnelle et l’approche simplifiée. Rappelez-vous que vous voulez évaluer l’égalité des ordonnées à l’origine après avoir déterminé que les pentes étaient égales. Éprouver l’égalité des ordonnées à l’origine quand les pentes diffèrent (ou, si vous préférez, quand il y a une interaction) est rarement sensé, peut facilement être mal interprété, et ne devrait être effectué que rarement.
De retour aux données de anc1dat.csv, en comparant la relation entre lfkl et lage entre les sexes, nous avions obtenu les résultats suivants pour le modèle complet avec interactions :
Anova(model.full1, type =3)
Anova Table (Type III tests)
Response: lfkl
Sum Sq Df F value Pr(>F)
(Intercept) 0.64444 1 794.8182 < 2.2e-16 ***
sex 0.00041 1 0.5043 0.4795
lage 0.07259 1 89.5312 4.588e-15 ***
sex:lage 0.00027 1 0.3367 0.5632
Residuals 0.07135 88
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
On avait déjà conclu que la pente ne varie pas entre les sexes (i.e. l’interaction n’est pas significative). Notez que la valeur de p associée au sexe (0.4795) n’est pas significative non plus.
De l’autre côté, selon l’approche traditionnelle, l’inférence quand à l’effet du sexe se fait à partir du modèle réduit (le modèle ANCOVA sensus stricto):
model.ancova<-lm(lfkl~sex+lage, data =anc1dat)Anova(model.ancova, type =3)
Anova Table (Type III tests)
Response: lfkl
Sum Sq Df F value Pr(>F)
(Intercept) 1.13480 1 1410.1232 <2e-16 ***
sex 0.00149 1 1.8513 0.1771
lage 0.14338 1 178.1627 <2e-16 ***
Residuals 0.07162 89
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Call:
lm(formula = lfkl ~ sex + lage, data = anc1dat)
Residuals:
Min 1Q Median 3Q Max
-0.093992 -0.018457 -0.000876 0.022491 0.081161
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.225533 0.032636 37.552 <2e-16 ***
sexMALE -0.008473 0.006228 -1.361 0.177
lage 0.327253 0.024517 13.348 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.02837 on 89 degrees of freedom
Multiple R-squared: 0.696, Adjusted R-squared: 0.6892
F-statistic: 101.9 on 2 and 89 DF, p-value: < 2.2e-16
Dans ce modèle, sex n’est pas significatif et on conclue donc que l’ordonnée à l’origine ne diffère pas entre les sexes. Notez que la valeur de p est plus petite (0.1771 vs 0.4795), ce qui reflète la puissance accrue de l’approche traditionnelle. Toutefois, les conclusions sont les mêmes : les ordonnées à l’origine ne diffèrent pas.
Exercice
En examinant les graphiques diagnostiques, vous noterez qu’il y a trois observations dont la valeur absolue du résidu est grande (cas 19, 49, et 50). Ces observations pourraient avoir un effet disproportionné sur les résultats de l’analyse. Éliminez-les et refaites l’analyse. Les conclusions changent-elles ?
model.ancova.nooutliers<-lm(lfkl~sex+lage, data =anc1dat[c(-49, -50, -19),])Anova(model.ancova.nooutliers, type =3)
Anova Table (Type III tests)
Response: lfkl
Sum Sq Df F value Pr(>F)
(Intercept) 1.09160 1 1896.5204 < 2e-16 ***
sex 0.00232 1 4.0374 0.04764 *
lage 0.13992 1 243.0946 < 2e-16 ***
Residuals 0.04950 86
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Call:
lm(formula = lfkl ~ sex + lage, data = anc1dat[c(-49, -50, -19),
])
Residuals:
Min 1Q Median 3Q Max
-0.058397 -0.018469 -0.000976 0.020696 0.040288
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.224000 0.028106 43.549 <2e-16 ***
sexMALE -0.010823 0.005386 -2.009 0.0476 *
lage 0.328604 0.021076 15.591 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.02399 on 86 degrees of freedom
Multiple R-squared: 0.7706, Adjusted R-squared: 0.7653
F-statistic: 144.4 on 2 and 86 DF, p-value: < 2.2e-16
Ouch! Les résultats changent.
Il faudrait donc rejeter l’hypothèse nulle et conclure que les ordonnées à l’origine diffèrent! Une conclusion qualitativement différente de celle obtenue en considérant toutes les données.
Pourquoi? Il y a deux raisons possibles :
Les valeurs extrêmes influencent beaucoup les régressions ou,
L’exclusion des valeurs extrêmes permet d’augmenter la puissance de détection d’une différence.
La première explication est moins plausible parce que les valeurs extrêmes n’avaient pas une grande influence (leverage faible). Alors, la deuxième explication est plus plausible et vous pouvez le vérifier en faisant des régressions pour chaque sexe sans et avec les valeurs extrêmes. Si vous le faites, vous noterez que les ordonnées à l’origine pour chaque sexe ne changent presque pas alors que leurs erreurs-types changent beaucoup.
Exercice
Ajustez une régression simple entre lfkl et lage pour l’ensemble complet de données et aussi pour le sous-ensemble sans les 3 valeurs déviantes. Comparez ces modèles avec les modèles d’ANCOVA ajustés précédemment. Que concluez-vous ? Quel modèle, d’après vous, a le meilleur ajustement aux données ? Pourquoi ?
Call:
lm(formula = lfkl ~ lage, data = anc1dat[c(-49, -50, -19), ])
Residuals:
Min 1Q Median 3Q Max
-0.055567 -0.017809 -0.002944 0.021272 0.044972
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.20378 0.02670 45.09 <2e-16 ***
lage 0.34075 0.02054 16.59 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.02441 on 87 degrees of freedom
Multiple R-squared: 0.7598, Adjusted R-squared: 0.7571
F-statistic: 275.2 on 1 and 87 DF, p-value: < 2.2e-16
Pour la régression simple (sans les valeurs extrêmes) on obtient un \(R^2\) de 0.76 et une erreur-type des résidus de 0.02441, En comparant à l’erreur-type des résidus du modèle d’ANCOVA (0.02399) on réalise que la qualité des prédictions est essentiellement la même, même en ajustant des ordonnées à l’origine différentes pour chaque groupe. Par conséquent, les bénéfices de l’inclusion d’un terme pour les différentes ordonnées à l’origine sont faibles alors que le coût, en terme de complexité du modèle, est élevé (33% d’augmentation du nombre de termes pour un très faible amélioration de la qualité d’ajustement). Si vous examinez les résidus de ce modèle, vous trouverez qu’ils sont à peu près OK.
Si on ajuste une régression simple sur toutes les données, on obtient:
model.linear<-lm(lfkl~lage, data =anc1dat)summary(model.linear)
Call:
lm(formula = lfkl ~ lage, data = anc1dat)
Residuals:
Min 1Q Median 3Q Max
-0.090915 -0.018975 -0.002587 0.021270 0.085273
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.21064 0.03089 39.19 <2e-16 ***
lage 0.33606 0.02376 14.14 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.0285 on 90 degrees of freedom
Multiple R-squared: 0.6897, Adjusted R-squared: 0.6863
F-statistic: 200.1 on 1 and 90 DF, p-value: < 2.2e-16
Encore une fois, l’erreur-type des résidus (0.0285) pour cette régression unique est semblable à la variance du modèle d’ANCOVA (0.02837) et le modèle simplifié prédit presque aussi bien que le modèle plus complexe. Ici encore, toutes les conditions d’application semblent remplies, si ce n’est de la valeur extrême.
Donc, dans les deux cas (avec ou sans les valeurs extrêmes), l’addition d’un terme supplémentaire pour le sexe n’ajoute pas grand-chose. Il semble donc que le meilleur modèle soit celui de la régression simple. Un estimé raisonnablement précis de la taille des esturgeons peut être obtenu de la régression commune sur l’ensemble des résultats.
Note: Il est fréquent que l’élimination de valeurs extrêmes en fasse apparaître d’autres. C’est parce que ces valeurs extrêmes dépendent de la variabilité résiduelle. Si on élimine les valeurs les plus déviantes, la variabilité résiduelle diminue, et certaines observations qui n’étaient pas si déviantes que cela deviennent proportionnellement plus déviantes. Notez aussi qu’en éliminant des valeurs extrêmes, l’effectif diminue et que la puissance décroît. Il faut donc être prudent.
14.6 Comparer l’ajustement de modèles
Comme vous venez de le voir, le processus d’ajustement de modèles est itératif. La plupart du temps il y a plus d’un modèle qui peut être ajusté aux données et c’est à vous de choisir celui qui est le meilleur compromis entre la qualité d’ajustement (qu’on essaie de maximiser) et la complexité (qu’on essaie de minimiser). La stratégie de base en ajustant des modèles linéaires (ANOVA, régression, ANCOVA) est de privilégier le modèle le plus simple si la qualité d’ajustement n’est pas significativement plus mauvaise. R peut calculer une statistique F vous permettant de comparer l’ajustement de deux modèles. Dans ce cas, l’hypothèse nulle est que la qualité d’ajustement ne diffère pas entre les deux modèles.
Exercice
En utilisant les données de anc1dat comparez l’ajustement du modèle ANCOVA et de la régression commune:
Analysis of Variance Table
Model 1: lfkl ~ sex + lage
Model 2: lfkl ~ lage
Res.Df RSS Df Sum of Sq F Pr(>F)
1 89 0.071623
2 90 0.073113 -1 -0.0014899 1.8513 0.1771
La fonction anova() utilise la différence entre la somme des carrés des deux modèles et la divise par la différence entre le nombre de degrés de liberté pour obtenir un carré moyen. Ce carré moyen est utilisé au numérateur et est divisé par la variance résiduelle du modèle le plus complexe pour obtenir la statistique F. Dans ce cas-ci, le test de F n’est pas significatif, et on conclut que les deux modèles ont une qualité d’ajustement équivalente, et qu’on devrait donc privilégier le modèle le plus simple, la régression linéaire simple.
Exercice
Refaites le même processus avec le données de anc3dat, ajustez le modèle complet avec interaction (LFKL~LAGE+LOCATE+LAGE:LOCATE) et sans interaction (LFKL~LAGE+LOCATE), Comparez l’ajustement des deux modèles, que concluez vous?
Solution
model.full.anc3dat<-lm(lfkl~lage+locate+lage:locate, data =anc3dat)model.ancova.anc3dat<-lm(lfkl~lage+locate, data =anc3dat)anova(model.full.anc3dat,model.ancova.anc3dat)
Analysis of Variance Table
Model 1: lfkl ~ lage + locate + lage:locate
Model 2: lfkl ~ lage + locate
Res.Df RSS Df Sum of Sq F Pr(>F)
1 88 0.051358
2 89 0.060448 -1 -0.0090901 15.575 0.0001592 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Cette fois-ci, le modèle plus complexe s’ajuste significativement mieux aux données (Pas surprenant puisque nous avions précédemment conclu que l’interaction est significative avec ces données).
14.7 Bootstrap
################################################################### Analyses Bootstrap# Analyses Bootstrap intervalles de confiance BCa# Préférable quand il y a un fort écart à la normalité# Bootstrap 95% BCa IC pour les coefficients de la régressionlibrary(boot)# Pour simplifier des futures modification du code dans ce fichier,# assignez les données à un objet mesdonneesmesdonnees<-anc3dat# créez une variable maformule contenant la formule du modèle à ajustermaformule<-as.formula(lfkl~lage+locate+lage:locate)# fonction pour obtenir les coefficients de régression à chaque itérationbs<-function(formula, data, indices){d<-data[indices, ]fit<-lm(formula, data =d)return(coef(fit))}# bootstrap avec 1000 réplicationsresultats<-boot(data =mesdonnees, statistic =bs, R =1000, formula =maformule)# afficher les résultatsresultatsboot_res<-summary(resultats)rownames(boot_res)<-names(resultats$t0)boot_resop<-par(ask =TRUE)for(iin1:length(resultats$t0)){plot(resultats, index =i)title(names(resultats$t0)[i])}par(op)# get 95% confidence intervalsfor(iin1:length(resultats$t0)){cat("\n", names(resultats$t0)[i],"\n")print(boot.ci(resultats, type ="bca", index =i))}
14.8 Test de Permutation
####################################################################### Test de Permutation## en utilisant le paquet `lmperm`# Pour simplifier des futures modification du code dans ce fichier,# assignez les données à un objet mesdonneesmesdonnees<-anc3dat# créez une variable maformule contenant la formule du modèle à ajustermaformule<-as.formula(lfkl~lage+locate+lage:locate)require(lmPerm2)# Ajustez le modèle voulu sur les données vouluesmonmodele<-lm(maformule, data =mesdonnees)# Calculez la valeur de p pour chaque termes à chaque permutation# Notez que lmp centre les variables numériques par défaut,# donc pour avoir des résultats consistants avec les modèles standards,# il faut :center=FALSEmonmodeleProb<-lmp(maformule, data =mesdonnees, center=FALSE,perm ="Prob")summary(monmodele)summary(monmodeleProb)