Introduction Bayesian statistics
Why make it simple when you could go Bayesian
2024-09-19
Prosecutor’s fallacy
Mixing up P[ A | B ] with P[ B | A ] is the Prosecutor’s Fallacy
small P evidence given innocence \(\neq\) small P of innocence given evidence
True Story 
- After the sudden death of two baby sons, Sally Clark was sentenced to life in prison in 1999
- Expert witness Prof Roy Meadow had interpreted the small probability of two cot deaths as a small probability of Clark’s innocence
- After a long campaign, including refutation of Meadow’s statistics (among other errors), Clark was cleared in 2003
- After being freed, she developed alcoholism and died in 2007
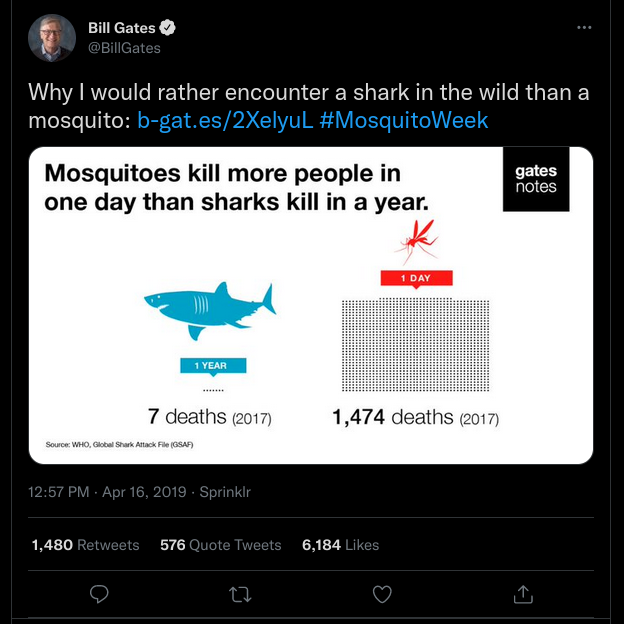
Meeting mosquitoes
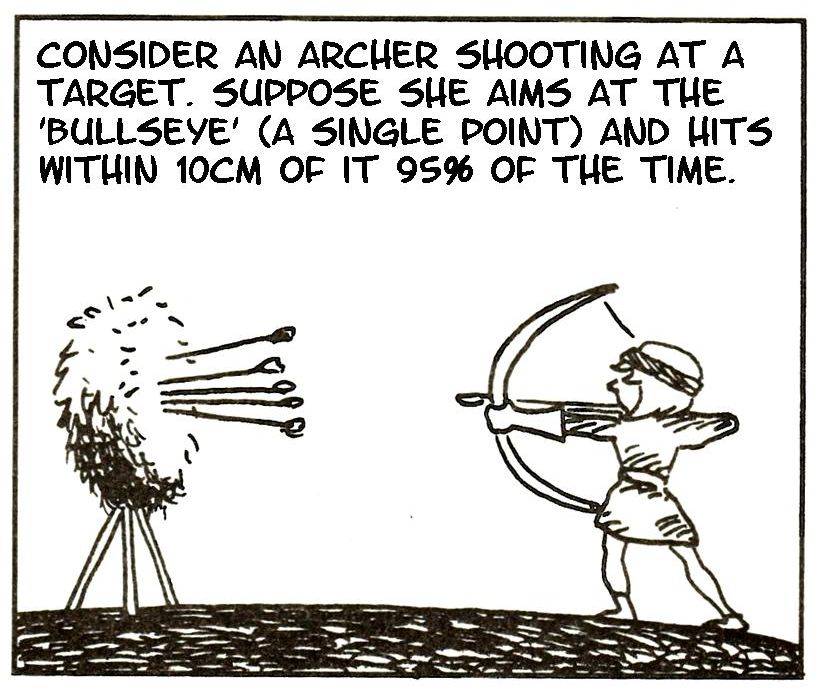
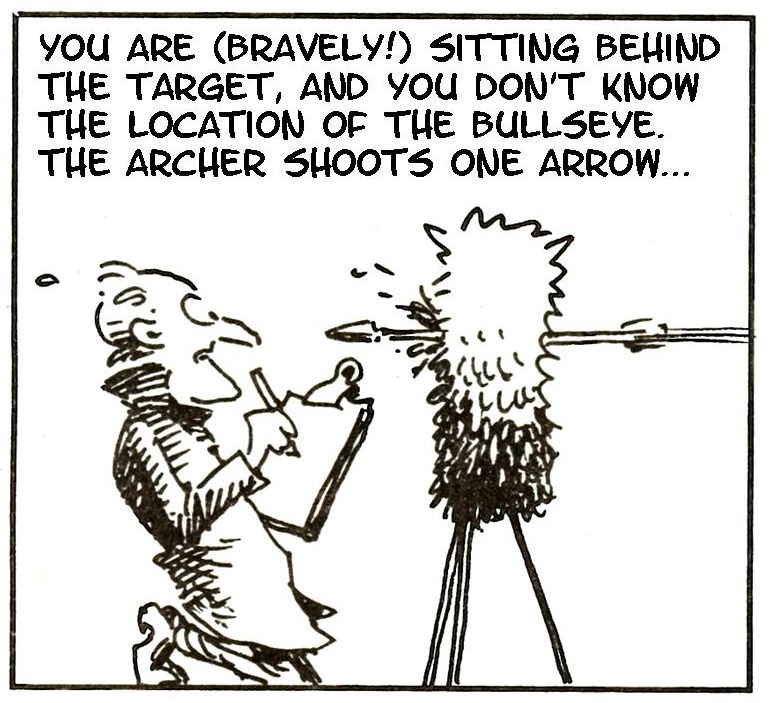


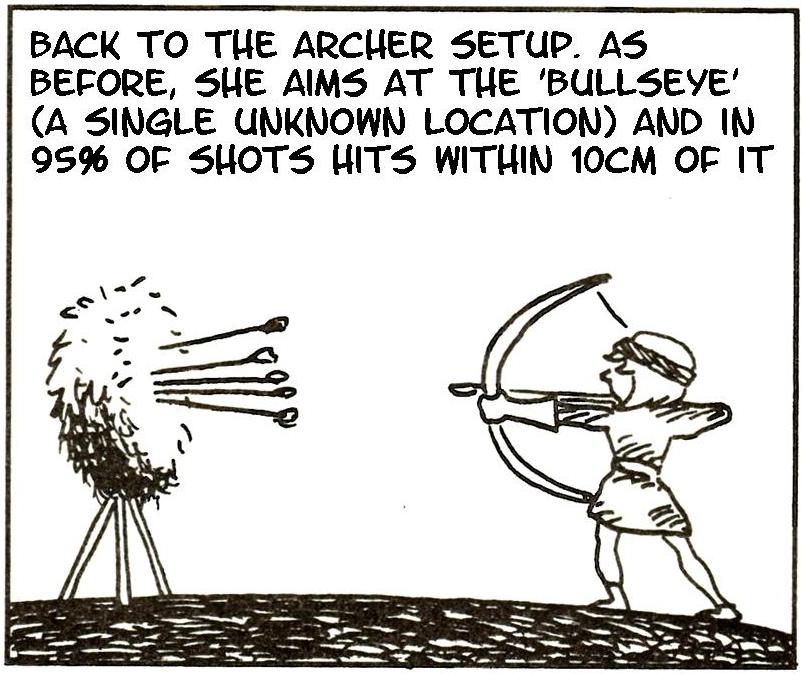






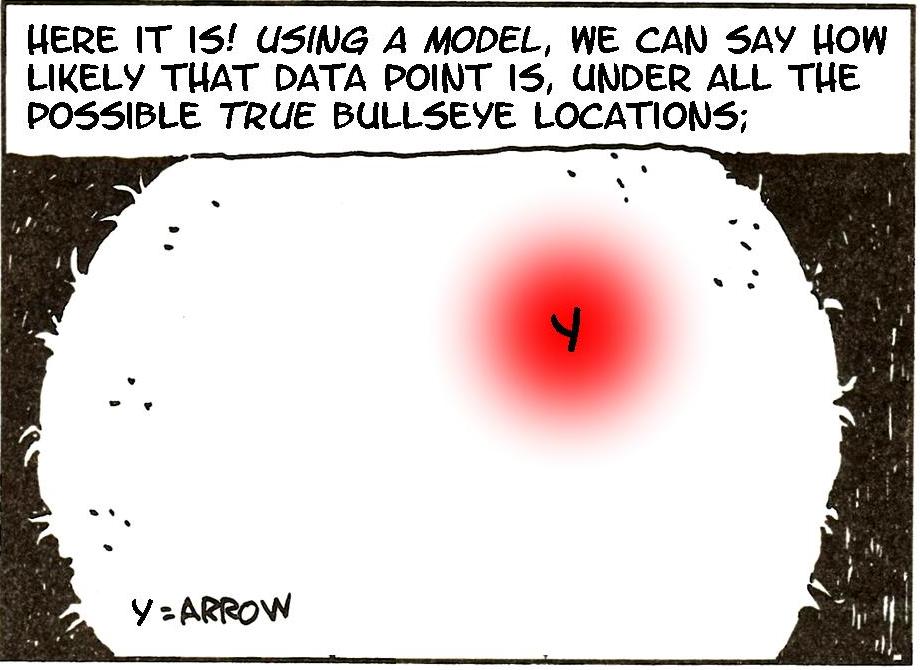
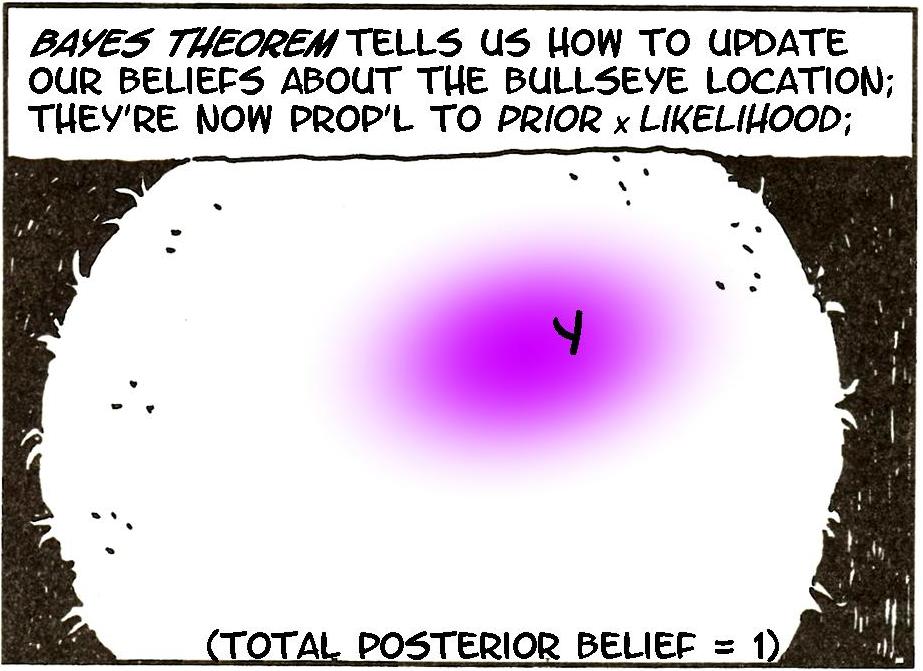
Here it is in practice
- Air France Flight 447 crashed in the ocean On June 1, 2009.
- Major wreckage recovered within 5 days. No blackbox
![]()

- Probability of blackbox location described via Bayesian inference
![]()
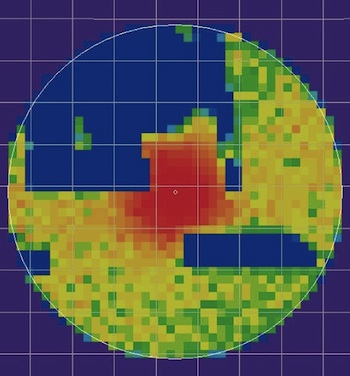
- Eventually, the black box was found in the red area
Updating knowledge

Updating knowledge

Updating knowledge

Updating knowledge

A Bayesian is one who, vaguely expecting a horse, and catching a glimpse of a donkey, strongly believes he has seen a mule
Where do priors come from
Use stickers or a survey in the hallway
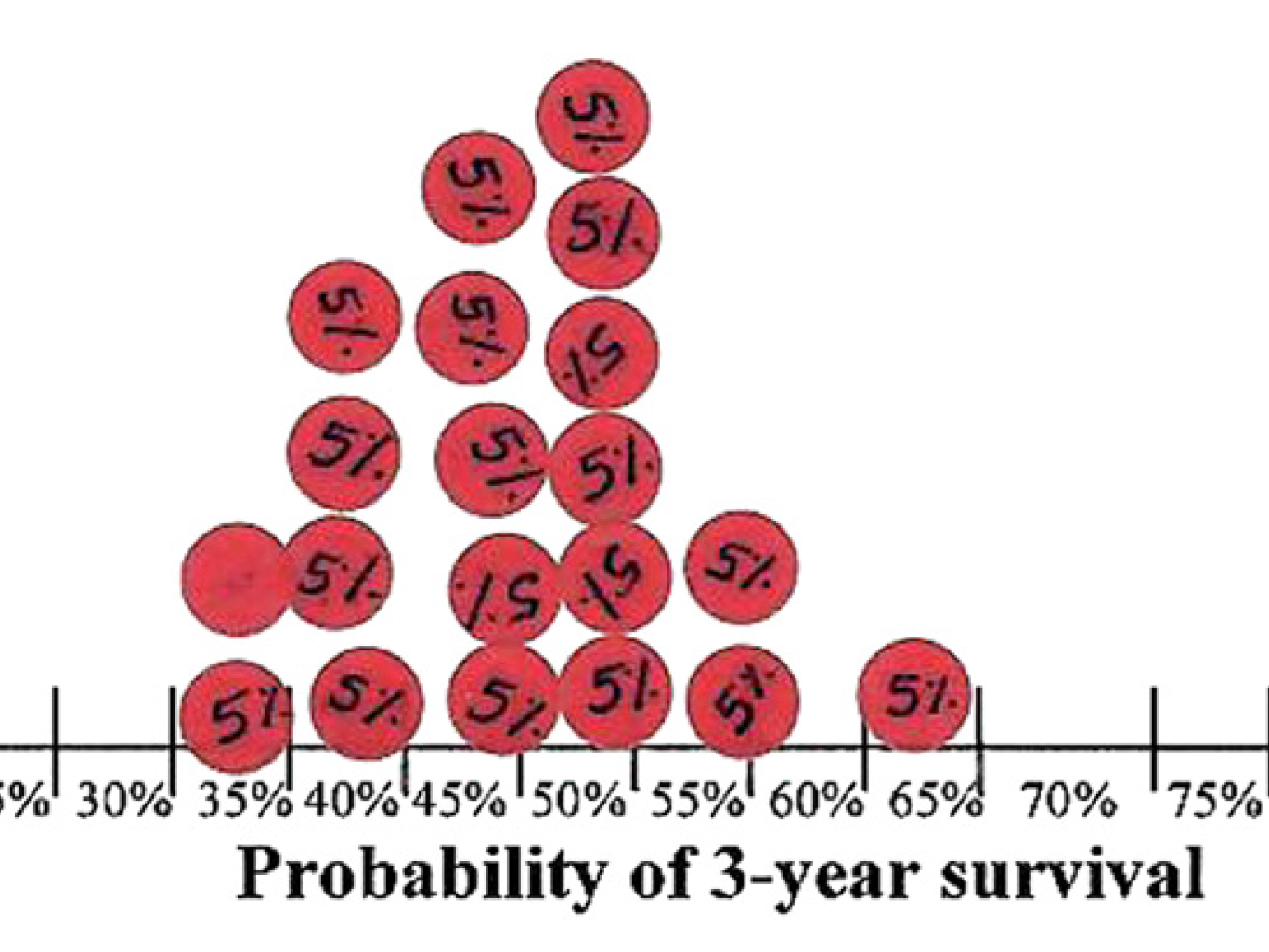
Use stickers (Johnson et al 2010, J Clin Epi) for survival when taking warfarin
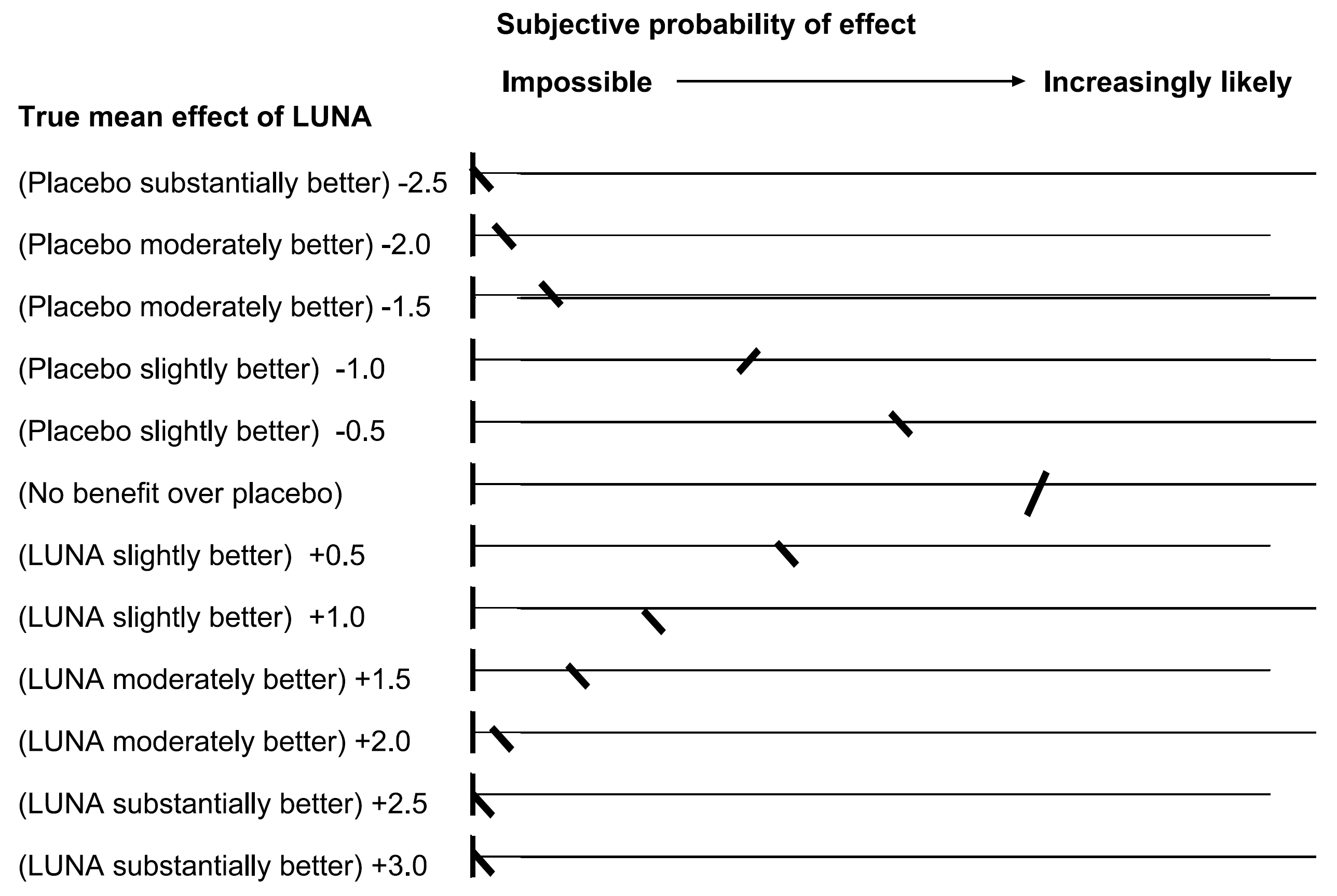
Normalize marks (Latthe et al 2005, J Obs Gync) for pain effect of LUNA vs placebo
Very informative data
When the data provide a lot more information than the prior

Priors here are dominated by the likelihood, and they give very similar posteriors – i.e. everyone agrees. (Phew!)
Flat priors
Using very flat priors to represent ignorance

Flat priors do NOT actually represent ignorance!
Bayesian \(\approx\) frequentist

Likelihood gives the classic 95% confidence interval can be good approx of Bayesian 95% Highest Posterior Density interval
Frequentist 😃 & Bayesian 😕
Prior strongly supporting small effects, and with data from an imprecise study

Happy modelling
